User Guides
IDU : Ingestion ponctuelle de données métier
L'objectif est de permettre à un utilisateur métier d'importer des fichiers à destination d'un espace de stockage (EdS).
Une interface "Ingestion" / Onglet IDU" est accessible depuis le portail quand son rôle le permet.
Si des données sont à importer en continue pour les besoins d'une application métier ou d'un traitement, nous vous conseillons d'utiliser le gestionnaire de sources (GDS).
Prérequis
L'espace de stockage cible doit exister :
- il a été créé au préalable par un administrateur de données et il a été spécifiquement identifié comme pouvant être alimenté par IDU (EdS de type
source) - un administrateur de données a créé l'espace d'import associé à cet espace de stockage
- l'utilisateur est autorisé à utiliser cet EdS et donc l'espace d'import associé
Lister des imports réalisés
Accéder à IDU via le portail métier -> Data Ingestion -> Onglet IDU. La page s'affiche avec la liste des imports de l'utilisateur connecté. Pour chaque import, on retrouve une synthèse des propriétés et du résultat.
Le résultat donne pour chaque étape, le nombre de fichiers concernés.
Détail d'un import
La sélection d'une ligne (un import) affiche le détail de ce dernier. Le détail contient les paramètres choisis lors de l'import et les détails sur les fichiers et leurs statuts.
Définir un espace d'import
Un espace d'import est un modèle qui permet de faciliter les imports des utilisateurs en mode simplifié : il précise l'endroit où seront déposés les fichiers et les marquants (labels et metadonnées) pré-définis.
Un administrateur de données définit un espace d'import en choisissant notamment :
- un nom pour l'espace, on préconise un nom qui permette à un utilisateur de bien reconnaitre les espaces qu'il utilisera
- l'EdS (bucket s3) et son sous-répertoire éventuel (il sera créé automatiquement s'il n'existe pas) où seront déposés les données : non modifiable lors de l'import
- les labels qui doivent être appliqués par défaut : modifiables lors de l'import
- les metadonnées complémentaires qui pourront être saisies par l'utilisateur lors de l'import
En option, l'administrateur peut donner le nom d'un salon sur lequel seront envoyées les notifications de succes et/ou d'échec des imports réalisés via cet espace. Les salons doivent exister au préalable (créés via l'IHM Element. L'Administrateur données créé le salon public et il invite le compte atheabot qui est en charge de diffuser les notifications).
La liste des EdS proposés à l'utilisateur dépend des attributs de l'utilisateur et des règles de la politique ABAC sur les EdS. Seuls les EdS de type source sont proposés.
Pour un EdS, la liste des labels propose les labels définis sur la (les) politque(s) associée(s) à l'EdS. Si un EdS ne possède pas de politique, il n'y aura pas de labels proposés, seules des metadatas libres seront disponibles.
Importer en mode simplifié
Le bouton + Importer permet d'accéder à la fonction d'import simplifiée : le choix de l'espace d'import va pré-remplir les formulaires de saisie des labels et métadonnées pour que l'utilisateur soit guidé dans son import.
L'utilisateur choisit l'espace, dépose ses fichiers et il est guidé pour saisir les labels et métadonnées .
Si l'utilisateur choisit d'importer un répertoire contenant une arborescence, l'arboresence sera créée dans minio et tous les fichiers porteront les labels et métadonnées saisis.
La liste des EdS proposés à l'utilisateur dépend des attributs de l'utilisateur. Par extension cette règle s'applique aux espaces d'import. Seuls les espaces compatibles avec les attributs de l'utilisateur sont proposés.
Importer en mode avancé
Le bouton d'import propose une option "mode avancé" pour les utilisateurs qui ont les droits associés (par exemple, les administrateurs de données).
En mode avancé, l'utilisateur choisit l'EdS et le sous répertoire et il choisit les labels et metadonnée sans être guidé.
Si l'utilisateur choisit d'importer un répertoire contenant une arborescence, l'arboresence sera créée dans minio et tous les fichiers porteront les labels et métadonnées saisis.
La liste des EdS proposés à l'utilisateur dépend des attributs de l'utilisateur. Par extension cette règle s'applique aux espaces d'import. Seuls les EdS de type source sont proposés.
Pour un EdS, la liste des labels propose les labels définis sur la (les) politque(s) associée(s) à l'EdS. Si un EdS ne possède pas de politique, il n'y aura pas de labels proposés, seules des metadatas libres seront disponibles. Si par inadvertance la clé de la metadata est une clé d'un label existant par ailleurs dans une autre politique, il ne pourra pas être posé sur la donnée.
Résultat de l'import et relance d'un import
Après validation de l'import, la liste des imports affiche une ligne contenant le statut de l'import :
- soit une barre de progression qui concerne la phase d'upload ;
- soit, lorsque les uploads sont finis, un état d'avancement composé des différentes étapes de l'import. Chaque étape indique le nombre de fichiers traités à un instant t par le processus.
A partir du panneau de détail, il est possible de reprendre un import, soit pour importer d'autres fichiers, soit pour rejouer l'import des fichiers en cas d'échec (les fichiers doivent être à nouveau choisis par l'utilisateur).
GDS : Ingestion de données depuis une source externe
Ce processus décrit comment le système permet d'utiliser les données de sources externes :
- les données situées à l'extérieur (accessibles via S3, sftp, http ou jdbc) vont être lues et déposées dans un EdS de l'infostructure (elles sont téléchargés vers un sas pour vérifier l'absence de virus puis déposées dans l'EdS cible choisi)
- l'EdS où les données sont déposées (un bucket S3) est appelé un EdS de type
source - les données brutes déposées dans cet EdS pourront alors être traitées via un traitement du datapipeline, une application ou exploitées via le datalab ou la dataviz.
Si des données sont à importer de manière ponctuelle pour les besoins d'une application métier ou d'un traitement, nous vous conseillons d'utiliser l'Ingestion de Donnée Utilisateur (IDU).
Prérequis
Les espaces de stockage nécessaires doivent être créés au préalable par un administrateur de données.
Déclarer une source externe
Sur le bandeau de gauche, il faut cliquer sur l'icône Sources Externes. Cliquez sur le bouton Ajouter une source en haut à droite de l’écran.
La création d’une source externe est décomposée en 5 étapes.
Etape 1 - Informations générales
Champs à remplir :
- Nom : le nom d’une source externe doit être unique (tous types de source confondus), ce champ est obligatoire.
- Description : une courte description de la source.
- Type de source : à choisir.
- Espace de stockage : cliquez sur la flèche du menu déroulant, les espaces de stockage disponibles sont alors listés.
Une fois que les champs sont complétés, cliquez sur suivant.
Etape 2 - Source
La liste des champs à saisir dans le formulaire de l’étape source varie en fonction du type de source choisi dans l’étape précédente.
Source de type S3 :
- Adresse de la source : adresse:port (du serveur source S3)
- Utilisateur : login de connexion sur le serveur source S3
- Mot de passe : mot de passe de connexion sur le serveur source S3
- Motif des noms de fichier : expression régulière permettant de sélectionner les noms des fichiers à ingérer
- Bucket : nom du bucket source contenant les fichiers à ingérer
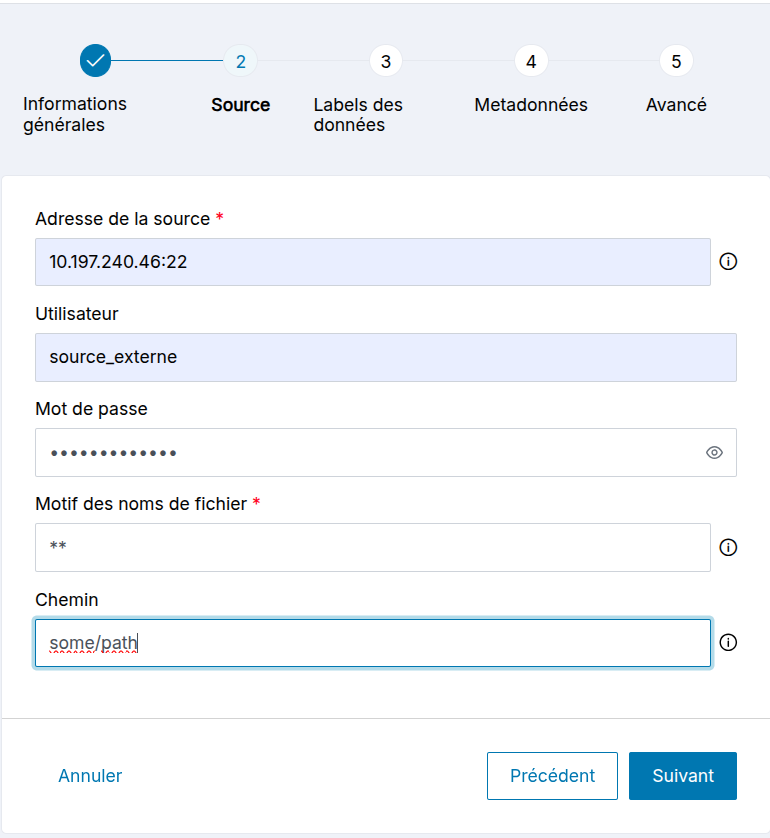
Source de type SFTP :
- Adresse de la source : adresse:port (du serveur source SFTP)
- Utilisateur : login de connexion sur le serveur source SFTP
- Mot de passe : mot de passe de connexion sur le serveur source SFTP
- Motif des noms de fichier : expression régulière permettant de sélectionner les noms des fichiers à ingérer
- Chemin : chemin absolu du dossier contenant les fichiers à ingérer
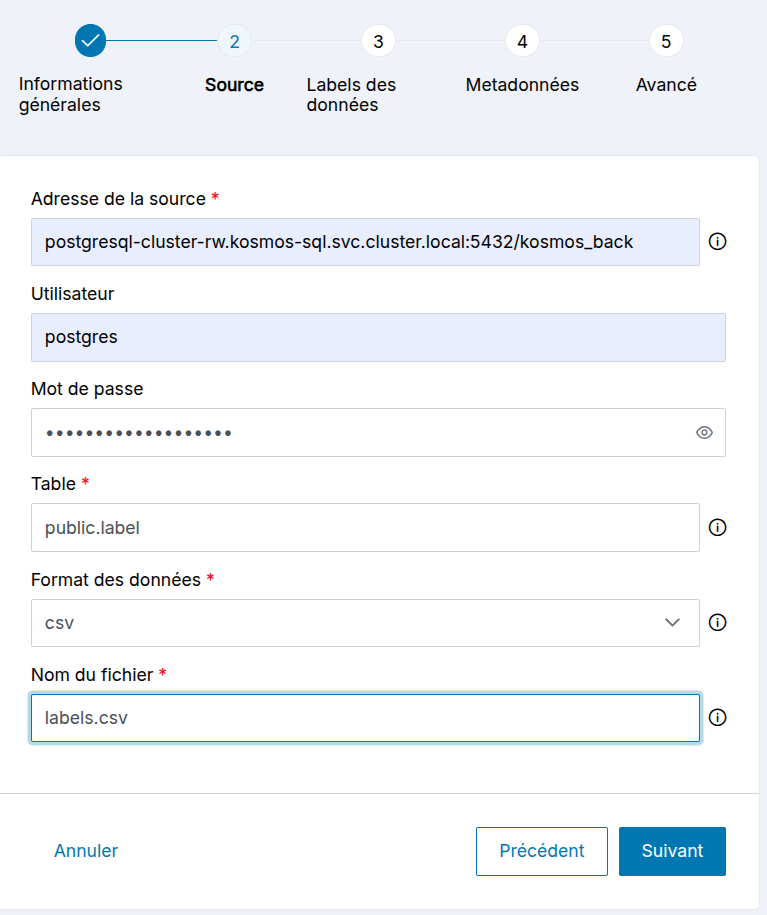
Source de type JDBC :
- Adresse de la source : adresse:port (du serveur source SQL)/base de données
- Utilisateur : login de connexion sur le serveur source SQL
- Mot de passe : mot de passe de connexion sur le serveur source SQL
- Table : table de la base de données
- Format des données : format des données écrites dans l'EDS cible sélectionné
- Nom du fichier : nom du fichier écrit dans l'EDS cible sélectionné
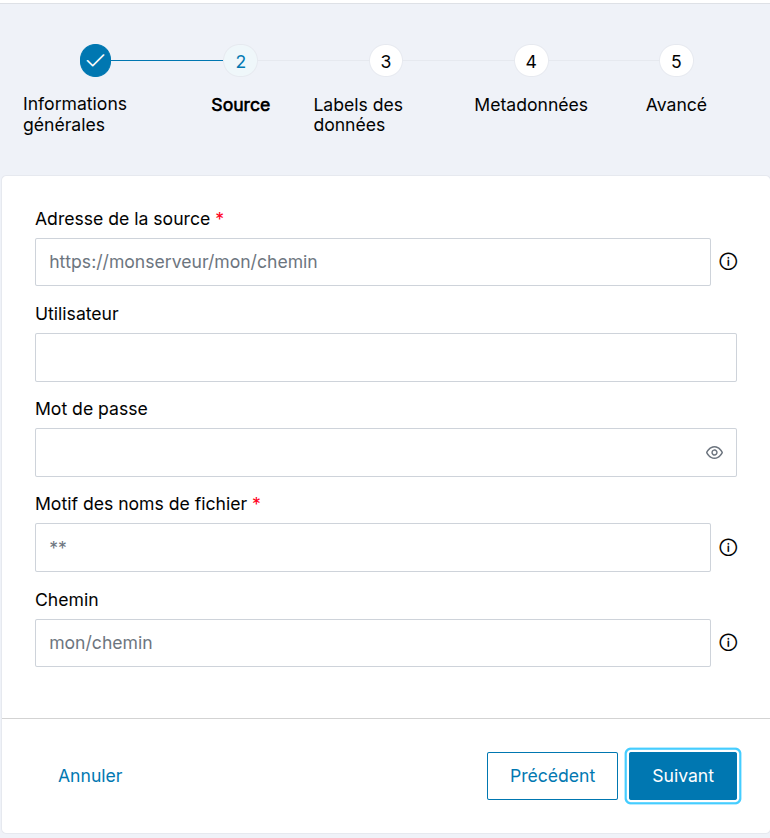
Source de type HTTP(S) :
- Adresse de la source : adresse:port (du serveur source HTTP(S))
- Utilisateur : login de connexion sur le serveur source HTTP(S)
- Mot de passe : mot de passe de connexion sur le serveur source HTTP(S)
- Motif des noms de fichier : expression régulière permettant de sélectionner les noms des fichiers à ingérer
- Chemin : suffixe de l'URL permettant d'accéder aux fichiers à ingérer
Le champ Motif des noms de fichier permet un parcours récursif en mettant 2 étoiles (par exemple **.txt). Si on met 1 seule étoile, le parcours n'est pas récursif.
Le champ Chemin précise à quel niveau on scrute la source externe. Ce Chemin est repris dans le bucket où sont déposés les fichiers ingérés.
Etape 3 - Labels des données
Formulaire de saisie des attributs de sécurité issus du référentiel des labels pour l'EdS choisi.
Il s'agit ici des labels propres à la (ou les) politique associée à l'EdS choisi à l'étape précédente.
Si l'EdS ne possède pas de politique alors il n'y a pas de labels proposés.
Etape 4 - Métadonnées
Formulaire de saisie des métadonnées libres (au format clé : valeur).
Attention, si une valeur de clé correspond à un label qui existe par ailleurs cette metadata ne sera pas stockée.
Etape 5 - Avancé
Cette section permet de définir des paramètres avancés en fonction du type de source.
La valeur du champ Filtre avancé ne doit pas être modifiée.
Après avoir validé le formulaire, la source est créée et vous êtes redirigé vers la page qui liste les sources externes disponibles.
Elle est automatiquement démarrée.
Désactiver / Supprimer un source externe
Il est possible de stopper une source puis de la relancer.
Elle peut aussi être modifiée.
Elle peut être supprimée après désactivation.
Sources
Paramétrage des sources externes :
Il faut que l'adresse de la source soit accessible depuis le Namespace kosmos-data de la plateforme.
Il faut donc prévoir de faire les entrées CoreDNS nécessaires pour le permettre.
Un fichier ingéré ne sera pas re-ingéré sauf si sa date de modification change.
Les sources HTTPS et SFTP supportent des expressions de glob POSIX
- SFTP
- S3
- HTTPS
- JDBC
La source SFTP permet d'ingérer à la racine du bucket cible l'arborescence de fichiers présente dans la source.
La source reste démarrée tant qu'elle n'est pas explicitement arrêtée.
Tout nouveau fichier ajouté dans l'arborescence source est copié dans l'arborescence cible.
La source S3 permet d'ingérer à la racine du bucket cible les fichiers présents dans le bucket source.
La source reste démarrée tant qu'elle n'est pas explicitement arrêtée.
Tout nouveau fichier ajouté dans le bucket source est copié dans le bucket cible.
La source HTTPS permet d'ingérer à la racine du bucket cible l'arborescence de fichiers présente dans la source.
On peut récupérer des fichiers depuis le protocole HTTP ou HTTPS en prefixant l'url avec/ou sans le "s".
La source reste démarrée tant qu'elle n'est pas explicitement arrêtée.
Tout nouveau fichier ajouté dans l'arborescence source est copié dans l'arborescence cible.
La source JDBC permet d'ingérer à la racine du bucket cible un fichier contenant les données d'une table SQL.
Ces données sont écrites dans un fichier texte sous un format populaire tel que json ou csv.
La source s'arrête quand elle a traité toutes les entrées de la table SQL.