User Guides
Utiliser un notebook
Cette procédure décrit comment utiliser Jupyter, via un notebook, pour :
- explorer les données déposées dans l'espace du DataScientist
- tester des fonctionnalités (Python, R et Scala) et visualiser les résultats obtenus
- sauvegarder les algorithmes dans gitlab
Étape 1 - Utilisation des données
Types de stockages disponibles
L'utilisateur a accès à 2 types de stockage pour ses données :
- son stockage local (home directory), dont la taille est limitée
- aux Espaces De Stockage (EdS) S3, PostgreSQL, etc. disponibles dans l'infostructure, mis en service via l'outil EdS :
- situés en Production, accessibles en lecture seule
- situés dans le Bac à Sable ou EID, accessibles en lecture et écriture
- déclarés dans Trino, accessibles via des requêtes Trino
Pour se connecter aux différents Espaces De Stockages, nous allons utiliser une librairie Python qui s'appelle keds.
Cette librairie permet de se connecter aux Espaces De Stockages suivants : Postgres, S3 (S3 avec Spark), OpenSearch, clickhouse (ne possède pas d'IAD). Elle traite de façon transparente pour l'utilisateur :
- l'utilisation des crédentials d'accès propres à l'EdS
- l'utilisation des IAD (hormis clickhouse) pour effectuer les contôles BeC si une politique est déployée
- l'utilisation du matricule de l'utilisateur connecté à Jupyter pour assurer les contôles BeC
Cette librairie utilise le "Nom de l'Espace De Stockage" : le nom technique de l'EdS
Par exemple : le nom technique est disponible quand on consulte les information d'un EdS dans l'outil EdS :
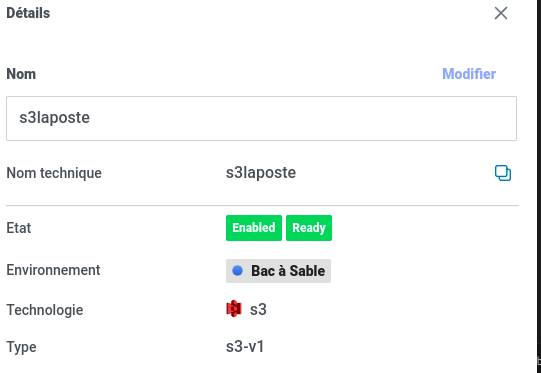
Les autres paramètres, facultatifs, sont :
- nom_application = "Nom de l'application" pour se connecter à S3 en utilisant Spark
Selon les langages et les librairies, les commandes pour accéder aux données sont différentes. Des exemple sont fournis suivant le type d'EdS.
Étape 2 - Accéder à un serveur
L'utilisation des serveurs : la création ou le changement des serveurs sont détaillés dans la procédure Changer de serveur
Développement en Python
Le développement en Python est disponible dans toutes les options du serveur. Pour développer en Python, il faut choisir le serveur Minimal (ou les autres serveurs en fonction de la librairie nécessaire).
Ci-après l'image :
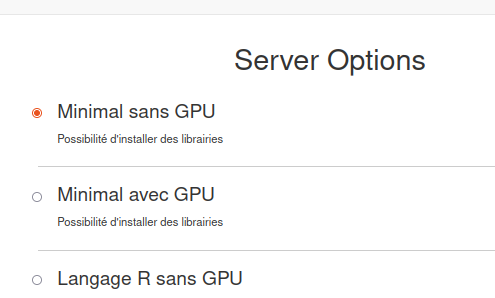
Appuyer sur le bouton start pour lancer le serveur.
Pour créer un nouveau notebook, choisir Python 3 (ipykernel) pour pouvoir créer un notebook en Python :

Import des librairies python dans le notebook
Les librairies sont des fichiers contenant un ensemble de fonctions, de classes et de variables prédéfinies et fonctionnelles. Si elles ne sont pas déjà présentes dans l'image du LAB, il faut les installer depuis le terminal du JupyterLab (pip install) pour pouvoir les importer dans le notebook.
Les librairies doivent avoir été importées au préalable dans la registry du système par un administrateur.
Résultat de l'algorithme sous la cellule
En cliquant sur le bouton run (sous la barre de menu) le kernel exécute le code et le résultat s'affiche sous la cellule.
Développement en R
Pour développer en R, il faut choisir le serveur Langage R.
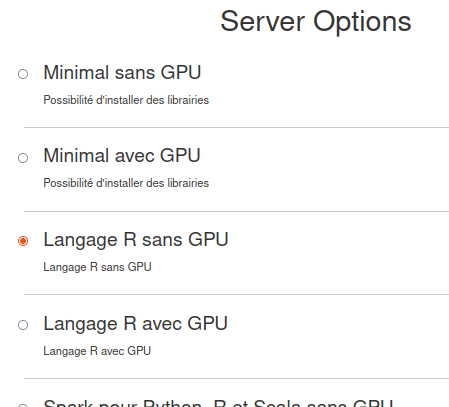
Appuyer sur le bouton start pour lancer le serveur.
Choisir le kernel R pour pouvoir développer en R.

Import des librairies R dans le notebook
Si les librairies ne sont pas déjà présentes dans l'image du LAB, il faut les installer depuis le terminal du JupyterLab (install.packages("chemin_vers_librairie", type="source")) pour pouvoir les importer dans le notebook.
Les librairies doivent avoir été importées au préalable dans le repo Gitea par l'administrateur. La doc gitea explique comment le faire
Par défaut dans la configuration de Jupyter un repository R est déclaré : le repository Gitea.
L'adresse de ce repo vient des variables d'environnement, soit la variable R_REPO pour le repo complet, à defaut, jupyterhub prendra le même repo que celui des packages python,
en supposant que c'est un repo Gitea.
Bien connaitre la disponibilité des packages ainsi que leur numéro de version dans le Gitea si on souhaite installer une version spécifique d'un package. Un dossier R/library est créé par défaut pour contenir les packages installés.
Dans un notebook R, pour installer le package suivant "withr", lancer la commande suivante :
install.packages("withr")
Pour désinstaller le package, lancer la commande suivante :
remove.packages("withr")
Des warnings peuvent apparaître :
Removing package from ‘/home/jovyan/R/library’
(as ‘lib’ is unspecified)
Ajouter dans ce cas l'option "lib" dans le remove.
Pour spécifier la version d'un package, vérifier au préalable qu'elle est disponible dans le repository.
L'exemple ci-dessous montre comment télécharger un package withr en version 2.5.2 alors que le repository contient 2.5.2 et 3.0.2.
repo_url <- Sys.getenv("R_REPO")
pkg_name <- "withr_2.5.2.tar.gz"
url <- sprintf("%s/src/contrib/%s", repo_url, pkg_name)
install.packages(pkg_name, repos = NULL)
Utilisation de Librairies R
Pour consulter les librairies de base installées dans R, exécuter le code suivant :
installed.packages()
available.packages()
Pour utiliser un de ces packages, exécuter :
library(httr)
library(withr)
library(datasets)
library(pacman)
require(zoo)

Pour consulter la liste des packages installés dans le Repository Manager, exécuter les commandes suivantes :
curl https://gitea.technique.artemis/api/packages/athea/cran/src/contrib/PACKAGES.gz --output /home/jovyan/test_packages/PACKAGES.gz
Dezipper le fichier :
gunzip PACKAGES.gz
Exécuter cette commande :
## lister les packages disponibles
read.dcf("PACKAGES")
Développement en SCALA
Pour développer en Scala, il suffit de choisir le serveur Scala pour python, R, Scala. Ci joint l'image :
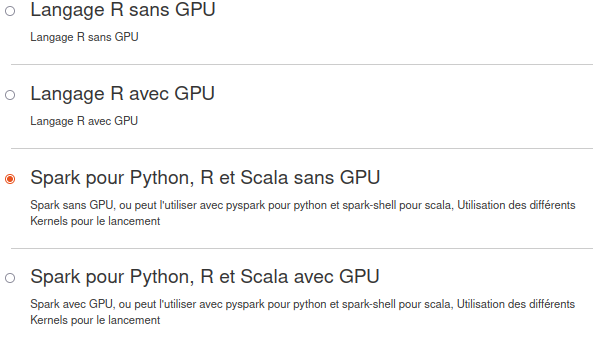
Appuyer sur le bouton start pour lancer le serveur.
Après le chargement de l'image, il faut choisir le kernel Apache Toree pour pouvoir développer en Scala.
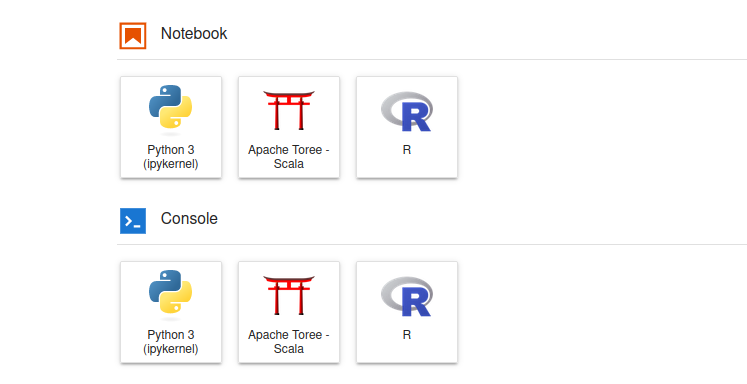
Exemples de code Scala
Les variables en Scala sont de trois types val, var, et def. Les variables de type val sont des variables fixes, immutables qu'on ne peut pas modifier. Les variables de type var peuvent être modifiées. Les variables de type def doivent être initialisées.
val nbre= 12
var nbre=13
def nbre=14
Création d'une classe qui permet de créer des nombres complexes :
class Complexe(reel: Double, imaginaire: Double) {
def re() = reel
def im() = imaginaire
def this (reel:Double)= this(reel,0)
def printInfo(): Unit = imaginaire match {
case 0 => println(s"The number is $reel")
case _ => println(s"The number complex is $reel and $imaginaire")
}
}
A l'intérieur de cette classe, la fonction printInfo() permet d'afficher le résultat d'une requête.
Ci-dessous un exemple d'utilisation :
val Nombre=new Complexe(1.5,4)
val Nbr=new Complexe(3)
Nombre.printInfo()
Nbr.printInfo()
Résultat obtenu :
The number complex is 1.5 and 4.0
The number is 3.0
Nombre = Complexe@62344da1
Nbr = Complexe@33795d20
Complexe@33795d20
Faire une fonction qui permet de charger un fichier CSV en utilisant du code Scala.
val df = spark.read
.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("client.csv")
Pour afficher les informations relatives au dataframe, utiliser les commandes suivantes :
df.show() /*pour afficher l'ensemble de la table*/
df.printSchema() /*pour afficher les différents types de variables présents dans la dataframe*/
Exemple de résultat :
+----------------------+
|firstname;lastname;age|
+----------------------+
| alice;green;28|
| bob;doe;27|
| clara;black;30|
+----------------------+
Création des cellules à charger et à exécuter
La cellule contient le code à exécuter (cliquer sur le bouton run), ce code est une requête interactive dans Jupyter.

Etape 3 - Stockage d'un algorithme dans GitLab
JupyterLab peut communiquer avec le GitLab via son terminal, se référer au chapitre sur son usage.
Créer votre propre template de notebook
Il peut arriver que vous ayez besoin d'une image personnalisée non-incluse. Pour :
- Ajouter des packages personnalisés
- Ajouter des bibliothèques dynamiques compilées manuellement
- Ajouter des versions différentes de dépendances (par exemple, CUDA)
- Autres outils personnalisés, SDK, clients SSH, noyaux, etc.
Voici un exemple d'image personnalisée qui ajoute des fonctionnalités de visualisation au noyau JupyterHub via le package jupyter-server-proxy.
Here is the requirements.txt file
jupyter-server-proxy
ipywidgets
tensorboard
folium
pandas
numpy
plotly
matplotlib
And the corresponding Dockerfile
# Always start from jupyter's minimal notebook or an image that has it as base
FROM quay.io/jupyter/minimal-notebook:python-3.12.10
# Make sure pip searches in your repository, no authentication required
ENV PIP_INDEX_URL="https://gitea.kosmos.athea/api/packages/athea/pypi/simple/"
ENV PIP_TRUSTED_HOST="gitea.kosmos.athea"
# Include your requirements.txt file
ADD requirements.txt ./
# Install the packages included in that requirements.txt file
RUN pip install --no-cache-dir -r requirements.txt
Ajouter ce template
Vous pouvez ajouter votre propre image créée à l'aide de l'exemple de la section précédente à la liste des images fournies en modifiant le fichier YAML de déploiement de JupyterHub pour cela en faire la demande à un Administrateur système.
Exemples d'accès aux EDS
Chargement de la librairie d'accès aux EdS
Pour se connecter aux Espaces, nous avons besoin de charger le package keds. Dans un terminal :
jovyan@jupyter-secadmin--test2:~$ pip install keds
Nous pouvons vérifier si le package est bien installé en faisant :
pip list | grep keds
Après avoir installé notre package, nous pouvons nous connecter aux Espaces De Stockage.
Accès aux EdS OpenSearch
Cette procédure décrit comment accéder aux Espaces de stockage (EdS) dans Jupyter, via un notebook (R ou python suivant le cas).
Langage Python
Nous allons utiliser la librairie keds pour pouvoir se connecter aux Espaces De Stockage de type OpenSearch :
import keds
from keds.es import connection
database_name = "nom technique de notre database opensearch"
client= connection(database_name)
Python - Ecriture dans un index
Pour écrire des informations sur notre index vous devez déclarer un document en format JSON :
document = {
'commentaire': 'sur Jupyter',
'nom': 'A2',
'codepostal': '32242'
}
res = client.index(index=index_name, body=document, headers={'Content-Type': 'application/json'})
print(res)
Résultats obtenus
{'_index': 'pkafebasdocs', '_type': '_doc', '_id': 'jSD7IocBbbvyiM8MNdRr', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 2, 'failed': 0}, '_seq_no': 0, '_primary_term': 1}
Plusieurs informations utiles dans ce JSON :
- l'état du document (créé ou pas)
- le type du document
- le nom de l'index
- l'identifiant du document qui est utile pour la lecture, ainsi que la version
On peut aussi spécifier la partie du résultat que l'on veut récupérer :
print(res['result'])
created
print(res['_id'])
jSD7IocBbbvyiM8MNdRr
Python - Lecture dans un index
Nous pouvons regarder les différentes informations d'un index existant. Pour cela vous devez connaître le nom de votre index. Si vous n'aviez rien spécifié à la création, le nom de votre index est le nom de votre base plus "-default".
Par exemple :
index_name = "pkafebasdocs-default"
index_info = client.indices.get(index=index_name)
print(index_info)
Résultats obtenus
{'pkafebasdocs-default': {'aliases': {}, 'mappings': {}, 'settings': {'index': {'creation_date': '1713961514560', 'number_of_shards': '2', 'number_of_replicas': '1', 'uuid': 'S9nuFQxjT_mPbbaOsBY8cQ', 'version': {'created': '135248227'}, 'provided_name': 'pkafebasdocs-default'}}}}
Ci-dessous vous trouverez d'autres exemples d'usages simples :
Python - Lecture d'un document
Pour lire le contenu d'un document présent dans votre index, il faut d'abord récupérer l'id du document jSD7IocBbbvyiM8MNdRr recherché, puis lancer les commandes :
response = client.get(index=index_name, id="jSD7IocBbbvyiM8MNdRr")
print(response['_source'])
Résultats obtenus
{'commentaire': 'sur Jupyter', 'nom': 'A2', 'codepostal': '32242'}
Python - Lecture de tous les documents
Nous pouvons lire tous les documents d'un index sans lui spécifier le numéro d'identifiant.
query = {
"query": {
"match_all": {}
}
}
response = client.search(index=index_name, body=query,size=10000)
for hit in response['hits']['hits']:
print(hit['_source'])
Résultats obtenus
{'took': 15, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 2, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'pp_test', '_type': '_doc', '_id': '2', '_score': 1.0, '_source': {'@timestamp': '2099-11-15T13:12:00', 'message': 'GET /search HTTP/1.1 200 1070000', 'user': {'id': 'toto'}}}, {'_index': 'pp_test', '_type': '_doc', '_id': '1', '_score': 1.0, '_source': {'year': '2011', 'director': 'Bennett Miller', 'title': 'Moneyball'}}]}}
{'@timestamp': '2099-11-15T13:12:00', 'message': 'GET /search HTTP/1.1 200 1070000', 'user': {'id': 'toto'}}
{'year': '2011', 'director': 'Bennett Miller', 'title': 'Moneyball'}
Langage R
Pour utiliser le package Python keds dans R, nous avons besoin du package reticulate. Le package est déjà installé ; il suffit de l'appeler au début du notebook R.
Connexion à l'EdS
Vous pouvez maintenant utiliser la librairie keds pour accéder à un index myedsname :
# Charger le package reticulate
library(reticulate)
# Utiliser l'environnement Python 3.12 et installer keds
use_python("/opt/conda/envs/python312_env/bin/python", required = TRUE)
reticulate::py_install(packages = "keds", pip = TRUE)
# Importer le module es de keds
keds_es <- import("keds.es", convert = FALSE)
# Créer un client opensearch
client <- keds_es$connection("myedsname")
print(client)
R - Lecture d’un index
# Définir directement le nom de l'index
index_name <- "myedsname"
# Accéder aux informations de l'index
index_info <- client$indices$get(index=index_name)
# Afficher les informations de l'index
print(index_info)
R - Lire tous les documents
Nous pouvons lire tous les éléments d’un index avec la requête ci-dessous :
# Définir directement le nom de l'index
index_name <- "myedsname"
# Définir la requête match_all
query <- dict(
query = dict(
match_all = dict()
)
)
# Exécuter la requête
response <- client$search(index = index_name, body = query)
# Afficher la réponse
print(response)
R - Écriture dans un index
Nous pouvons lire l'ensemble des éléments d'un index, avec la requête ci-dessous :
# Définir l'index cible pour votre EdS
database_name <- "myedsname"
index_name <- paste0(database_name, "-default")
# Définir le document à écrire
document <- list(
comment = "sur Jupyter",
name = "A2",
zip_code = "32242"
)
# Ajouter le document dans l'index
res <- client$index(
index = index_name,
body = document,
headers = list("Content-Type" = "application/json")
)
# Afficher la réponse
doc_id <- res$`_id`
print(doc_id)
# Récupérer le document par ID
response <- client$get(index = index_name, id = doc_id)
print(response$`_source`)
Accès aux EdS PostgreSQL
Cette procédure décrit comment accéder aux Espaces de stockage (EdS) dans Jupyter, via un notebook (R ou python suivant le cas).
Avec le langage Python
Nous allons nous connecter à Postgres en utilisant la librairie keds :
import keds
from keds.pg import connection
database_name = "nom technique de la database" # disponible via l'IHM S-EdS
table_names=connection(database_name)
Python - Lecture
Le programme suivant permet de lister les différentes tables présentes dans notre database via un dataframe :
from sqlalchemy import inspect
inp=inspect(table_names)
print(inp.get_table_names())
Nous allons lire les informations d'une table :
import pandas as pd
df = pd.read_sql_query('SELECT * FROM t_laposte', table_names)
df.head()
df.columns #pour voir les colonnes
df.dtypes #pour voir les types
print( df.head(10)) # pour afficher les 10 premières lignes
- df.head() permet d'afficher les premiéres lignes du dataframe
- df.tail() permet d'afficher les derniéres ligne du dataframe
On peut spécifier le nombre de lignes qu'on veut afficher, par exemple :
- df.head(10)
Résultats obtenus
code_postal nom_commune coordonnees_gps confidentialite
0 31170 TOURNEFEUILLE 123.456 NP
1 31000 TOULOUSE 123.456 NP
2 37000 TOURS 123.456 NP
3 99000 TOLEDE 654.456 DR
4 99000 TOMBOUCTOU 999.456 DR
5 12345 ARRAS 566.456 NP
6 23456 ABBEVILLE 566.456 NP
7 34567 AZERTY 00000.111 DR_SF
8 97150 GOSIER 123.456 NP
9 97500 SAINTE-ROSE 123.456 NP
Python - Ecriture
Nous allons créer un objet SQLAlchemy Table qui représente la table dans laquelle nous souhaitons écrire. Nous allons utiliser la fonction Table() et transmettre le nom de la table, les métadonnées et toutes les définitions de colonne.
from sqlalchemy import create_engine, Table, MetaData, text
# ouvrir une connection sur la base
conn = engine.connect()
trans = conn.begin() # Démarre une transaction
# Chargement de la table
metadata = MetaData()
mytable = Table('t_laposte', metadata, autoload_with=engine)
# Insertion (dans un begin pour que le commit soit fait)
conn.execute(mytable.insert(), {
'code_postal': '12345',
'nom_commune': 'PARIS',
'coordonnees_gps': '12.345, 6.789',
'confidentialite': 'DR'
})
trans.commit() # Force le commit
#relecture
result = conn.execute(text("SELECT * FROM t_laposte WHERE nom_commune = 'PARIS' and confidentialite = 'DR'"))
for row in result:
print(row)
conn.close() # Fermeture propre de la connexion
Avec le langage R
Vous pouvez maintenant utiliser la librairie keds pour accéder à une base de données myedsname:
# Charger le package reticulate
library(reticulate)
# Utiliser l'environnement Python
use_python("/opt/conda/envs/python312_env/bin/python", required = TRUE)
# Installer les dépendances
reticulate::py_install(packages = c("keds", "sqlalchemy"), pip = TRUE)
# Importer le module pg de keds
keds_pg <- import("keds.pg", convert = FALSE)
# Créer le client pg
client <- keds_pg$connection("myedsname","EID")
# Importer inspect
inspect <- import("sqlalchemy", convert = TRUE)$inspect
# Créer l'inspecteur
inp <- inspect(client)
# Obtenir les noms des tables
print(inp$get_table_names())
R - Lecture
Pour effectuer la lecture d'une donnée :
# Charger le module pandas en Python
reticulate::py_install(packages = "pandas", pip = TRUE)
pd <- import("pandas", convert = FALSE)
# Lire les données depuis la base PostgreSQL
df <- pd$read_sql_query('SELECT * FROM t_laposte', client)
# Afficher les 10 premières lignes du DataFrame
print(df$head(10L))
print(df$tail(10L))
print(df$columns)
R - Ecriture
Pour écrire des données, utilisez le code suivant :
# Importer les modules nécessaires via reticulate
sqlalchemy <- import("sqlalchemy", convert = FALSE)
MetaData <- sqlalchemy$MetaData
Table <- sqlalchemy$Table
Column <- sqlalchemy$Column
String <- sqlalchemy$String
# Configurer la table et les colonnes avec SQLAlchemy
metadata <- MetaData()
mytable <- Table(
't_laposte', metadata,
Column('code_postal', String),
Column('nom_commune', String),
Column('coordonnees_gps', String),
Column('confidentialite', String)
)
Choisir les données à insérer:
# Charger SQLAlchemy
sqlalchemy <- import("sqlalchemy", convert = FALSE)
MetaData <- sqlalchemy$MetaData
Table <- sqlalchemy$Table
metadata <- MetaData()
# Utiliser les informations de la table
mytable <- Table(
't_laposte',
metadata,
autoload_with = client
)
# Préparer l'insertion
insert_stmt <- mytable$insert()$values(
code_postal = '02430',
nom_commune = 'GAUCHY',
coordonnees_gps = '69.2667',
confidentialite = 'NP'
)
# Exécuter l'insertion
conn <- client$connect()
tx <- conn$begin()
conn$execute(insert_stmt)
tx$commit()
conn$close()
print("INSERT OK ✓")
# Vérifier si l'insertion a réussi
df <- pd$read_sql_query(
"SELECT * FROM t_laposte WHERE nom_commune='GAUCHY'",
client
)
print(df$head(10L))
Accès aux EdS s3
Cette procédure décrit comment accéder aux Espaces de stockage (EdS) dans Jupyter, via un notebook (R ou pyhton suivant le cas).
Avec le langage Python
Nous allons utiliser la librairie keds pour pouvoir se connecter aux Espaces De Stockage de type S3 :
from keds.s3 import connection
database_name = "nom technique de votre bucket"
minioClient = connection(database_name)
Python - Lister les différents éléments du bucket
objects = minioClient.list_objects(database_name,recursive=True)
print(objects)
for obj in objects:
print(obj.object_name)
Résultats obtenus
<generator object Minio._list_objects at 0x7f257a1ddc40>
Laposte_CDSF_K.txt
Laposte_DR_A.txt
Laposte_DR_H.txt
Laposte_DR_L.csv
Laposte_DR_V.csv
Laposte_NP_T.txt
Nous pouvons avoir une erreur si le bucket est vide.
Python - Lire un document du bucket
response=minioClient.get_object(database_name, "Laposte_DR_H.txt")
print(response.read())
ou pour un document CSV :
from io import StringIO
response=minioClient.get_object(database_name, "Laposte_DR_HL.csv")
data=response.read().decode("iso-8859-1")
df=pd.read_csv(StringIO(data))
df.head()
Avec le langage python - Ecriture
Nous pouvons écrire dans un bucket (Bac à Sable ou EID uniquement) en utilisant le code suivant :
import io
data ="mettre le message ou une information"
data_bytes = data.encode('utf-8')
data_stream = io.BytesIO(data_bytes)
try:
minioClient.put_object(database_name, "Laposte_DR_H.txt", data_stream , len(data_bytes))
except Exception as ex:
raise ex
Si on veut ajouter des données sur un fichier déjà existant, on doit utiliser la fonction fput_object() de minio. On spécifie le nom du bucket et le nom du fichier. Ci-dessous un exemple de code :
Si des metadata sont présentes sur le fichier ciblé, le fput va les supprimer.
file_name="Laposte_DR_H.txt"
new_contents = ' - Welcome to my bucket!'
file_data = client.get_object(database_name, file_name)
file_contents = file_data.read().decode('utf-8')
file_contents += new_contents
client.fput_object(database_name, file_name, file_contents.encode('utf-8'), len(file_contents))
print('New contents appended to file in bucket successfully.')
Langage Spark
L'accès à S3 via Spark nécessite de lancer un lab avec l'image "Spark pour python, R et Scala sans GPU".
Pour se connecter à S3, nous allons utiliser la librairie keds :
!pip install pyspark
from keds.sparkSession import connection
database_name = "s3laposte"
nom_application= "test spark3"
spark = connection(database_name, nom_application)
Spark - lire un fichier
"""SimpleApp.py"""
from pyspark.sql import SparkSession
logFile = "/home/jovyan/SomeFile.txt" # Should be some file on your system
spark = SparkSession.builder.appName("SimpleApp").getOrCreate()
logData = spark.read.text(logFile).cache()
numAs = logData.filter(logData.value.contains('a')).count()
numBs = logData.filter(logData.value.contains('b')).count()
print("Lines with a: %i, lines with b: %i" % (numAs, numBs))
spark.stop()
Spark - Lire le contenu fichier texte
Pour un fichier texte :
df = spark.read.text("s3a://s3laposte/Laposte_NP_T.txt")
df.show()
Résultats obtenus
+--------------------+
| value|
+--------------------+
|Code_commune_INSE...|
|64531;TABAILLE US...|
|33518;TABANAC;335...|
|9305;TABRE;9600;T...|
|58283;TACONNAY;58...|
|8435;TAGNON;8300;...|
|98745;TAHAA;98733...|
|98745;TAHAA;98733...|
|98745;TAHAA;98733...|
|98747;TAIARAPU ES...|
|98748;TAIARAPU OU...|
|17436;TAILLEBOURG...|
|25555;TAILLECOURT...|
|66199;TAILLET;664...|
|8437;TAILLY;8240;...|
|26347;TAIN L HERM...|
|71532;TAIZE;71250...|
|79321;TAIZE;79100...|
|16378;TAIZE AIZIE...|
|98749;TAKAROA;987...|
+--------------------+
only showing top 20 rows
Spark - Lire le contenu fichier CSV
df2 = spark.read.text("s3a://s3laposte/Laposte_DR_V.csv")
df2.show()
Résultats obtenus
+--------------------+
| value|
+--------------------+
|Code_commune_INSE...|
|98831;VOH;98883;O...|
|97133;VIEUX FORT;...|
|97134;VIEUX HABIT...|
|95678;VILLIERS AD...|
|95627;VALLANGOUJA...|
|95628;VALMONDOIS;...|
|95656;VIENNE EN A...|
|95676;VILLERS EN ...|
|95637;VAUREAL;954...|
|95641;VEMARS;9547...|
|95675;VILLERON;95...|
|94076;VILLEJUIF;9...|
|94074;VALENTON;94...|
|94075;VILLECRESNE...|
|94081;VITRY SUR S...|
|94077;VILLENEUVE ...|
|93074;VAUJOURS;93...|
|92077;VILLE D AVR...|
|92075;VANVES;9217...|
+--------------------+
only showing top 20 rows
Tips
Actions
On peut effectuer quelques calculs (par exemple : show, count).
count = df.count()
print("Nombre total de lignes:", count)
Lister des colonnes
Commandes pour filtrer ou chercher des valeurs :
filtered_df = df.filter(df.value.contains("bas"))
filtered_df.show()
Commandes pour sélectionner des variables :
selected_df = df.select("value")
selected_df.show()
Transformer des données :
Utilisez la méthode withColumn pour ajouter ou transformer des colonnes dans votre DataFrame
from pyspark.sql.functions import upper
transformed_df = df.withColumn("uppercase_value", upper(df["value"]))
transformed_df.show()
Regroupement et agrégation :
Utilisez les méthodes groupBy et les fonctions d'agrégation pour regrouper et calculer des statistiques sur vos données.
from pyspark.sql.functions import count
grouped_df = df.groupBy("value").agg(count("*").alias("count"))
grouped_df.show()
Tri des données :
Utilisez la méthode orderBy pour trier vos données en fonction d'une ou plusieurs colonnes.
sorted_df = df.orderBy("value")
sorted_df.show()
On peut utiliser la fonction "union" si les dataframes ont les mêmes nombres de colonnes :
df_avec_nouvelle_ligne = df.union(transformed_df)
df_avec_nouvelle_ligne.show()
On peut utiliser la fonction "join" :
On peut spécifier les paramétres "on" peut prendre le nom d'une colonne et le paramétre "how" avec les paramétres suivants :"inner", "left","right", "full".
df_avec_nouvelle_ligne = df.join(transformed_df)
df_avec_nouvelle_ligne.show()
On peut enregistrer le résultat d'un dataframe dans s3, en utilisant la commande suivante :
transformed_df.write.text("s3a://buckets/chemin/vers/resultats/")
Aprés avoir fini vos différentes manipulations veuillez fermer la connexion en faisant
spark.stop()
Pour ajouter une ligne à un DataFrame dans Apache Spark, vous ne pouvez pas simplement ajouter une ligne directement à un DataFrame existant, car les DataFrames sont immuables.
Avec le langage R - Lecture s3
Vous pouvez maintenant utiliser la librairie keds pour accéder à un bucket myedsname :
# Charger le package reticulate
library(reticulate)
# Utiliser l'environnement Python 3.12 et installer keds
use_python("/opt/conda/envs/python312_env/bin/python", required = TRUE)
reticulate::py_install(packages = "keds", pip = TRUE)
# Importer le module s3 de keds
keds_s3 <- import("keds.s3", convert = FALSE)
# Créer le client MinIO
minioClient <- keds_s3$connection("myedsname")
Dans R les objects generator ne peuvent pas être créer en liste pour faire une boucle for. Veuillez connaitre les éléments qui se trouve dans votre bucket.
Avec le langage R - Lecture
# Lister les objets dans le bucket
objects <- minioClient$list_objects("myedsname", recursive = TRUE)
# Convertir en liste R
objects_list <- iterate(objects)
# Afficher le résultat
cat("Objets récupérés :\n")
for (obj in objects_list) {
print(obj$object_name)
}
Avec le langage R - Ecriture
Dans cet exemple nous allons ingérer de nouvelles données :
# Nom du fichier à lire et écrire
file_name <- "fichier1.csv"
# Nouvelle ligne à ajouter
new_contents <- "0183;charlevilles;51141;charlevilles;;45.8485624628. 5.44711117486;DR"
# Lire le contenu existant du fichier
file_contents <- ""
tryCatch({
file_data <- minioClient$get_object("myedsname", file_name)
file_contents <- file_data$read()$decode('utf-8')
}, error = function(e) {
cat("Erreur lors de la lecture des données existantes ou fichier introuvable : ", e$message, "\n")
})
# Ajouter les nouvelles données au contenu existant
file_contents <- paste0(file_contents, new_contents)
# Créer un fichier temporaire et écrire les données mises à jour
temp_file <- tempfile()
write(file_contents, temp_file)
# Télécharger le fichier temporaire dans le bucket MinIO
tryCatch({
minioClient$fput_object("myedsname", "nouveaufichier.csv", temp_file)
cat("Données mises à jour avec succès dans le fichier", "nouveaufichier.csv", "\n")
}, error = function(e) {
cat("Erreur lors de l'écriture des données :", e$message, "\n")
})
# Supprimer le fichier temporaire
unlink(temp_file)
Si des metadata sont présentes sur le fichier, le fput va les supprimer.
Accès aux EDS clickhouse
L'accès aux EDS clickhouse se fait avec la bibliothèqe keds.
Téléchargement de la librairie
Pour se connecter aux Espaces, nous avons besoin de charger le package keds. Dans un terminal :
jovyan@jupyter--test2:~$ pip install keds
Avec le langage Python - Lecture CH
C'est la bibliothèque "clickhouse_driver" qui est utilisée.
Nous allons utiliser la librairie keds pour pouvoir se connecter aux Espaces De Stockage de type clickhouse :
import keds
from keds.clickhouse import connection
database_name = "ivvqchbas"
client= connection(database_name)
Puis nous pouvons lire des données et écrire des données (si l'EDS est dans le bac à sable).
Vérification database, tables
if client:
result = client.execute("SELECT version()")
print(f"Version de ClickHouse : {result[0][0]}")
result = client.execute("SHOW DATABASES")
for row in result:
print(row[0])
else:
print("Connexion échouée")
tables = client.execute(f"SHOW TABLES FROM {database_name}")
for table in tables:
print(table[0])
Lecture
# Fonction pour lire les articles
resultats = client.execute('SELECT journal, theme, texte FROM t_articles')
print(resultats)
Ecriture
def inserer_articles(articles):
client.execute(
'INSERT INTO t_articles (journal, theme, texte) VALUES',
articles
)
# Exemple d'insertion
articles_exemple = [
('Le Monde', 'politique', 'Le gouvernement annonce une réforme.'),
('Libération', 'loisirs', 'Un nouveau musée ouvre ses portes à Paris.')
]
inserer_articles(articles_exemple)
Accéder aux espaces de stockage vStore
Cette procédure décrit comment accéder aux espaces de stockage vStore (SSS) depuis Jupyter, à l’aide d’un notebook Python.
Connexion KEDS au vStore
La connexion au vStore peut également se faire via HTTP, en utilisant la variable d’environnement OAUTH2_ACCESS_TOKEN et la bibliothèque Python Athea KEDS.
Vous pouvez rafraîchir votre variable OAUTH2_ACCESS_TOKEN avec le code suivant :
import keds.vstore
from keds.vstore import connection
import json
import requests
import os
response = requests.get(f"{os.environ['JUPYTERHUB_API_URL']}/users/{os.environ['JUPYTERHUB_USER']}",
headers={'Authorization': f"token {os.environ['JUPYTERHUB_API_TOKEN']}"})
os.environ['OAUTH2_ACCESS_TOKEN'] = response.json()['auth_state']['access_token']
Lecture
Si un espace de données Vstore EdS nommé myeds est défini avec une entité laposte, il est possible de lire des données depuis cet espace. Exemple:
database_name = "myeds"
httpclient = connection(database_name)
httpclient['client'].request(
'GET',
'/v0/myeds/entities/laposte',
headers=httpclient['headers']
)
# Vider le buffer
res = httpclient['client'].getresponse()
print(f"HTTP {res.status} {res.reason}")
data = res.read().decode()
# Affichage de la réponse
try:
parsed = json.loads(data)f
print(json.dumps(parsed, indent=4, ensure_ascii=False))
except json.JSONDecodeError:
print("Réponse :")
print(data)
Consultez la documentation développeur de l’API vStore pour plus de détails sur les fonctionnalités disponibles.
Écriture
Si un espace de données Vstore EdS nommé myeds est défini avec une entité laposte, il est possible d’écrire des données dans cet espace. Exemple:
database_name = "myeds"
httpclient = connection(database_name)
# Données à envoyer (POST)
payload = {
"values": [
{
"id": "10",
"nom_commune": "Foix",
"code_postal": "09000",
"coordonnees_gps": "54.7009,15.2683",
"auteur": "myuser",
"confidentialite": "NP"
}
]
}
# Requête POST
httpclient['client'].request(
'POST',
'/v0/myeds/entities/laposte',
headers=httpclient['headers'],
body=json.dumps(payload)
)
# Vider le buffer
res = httpclient['client'].getresponse()
print(f"HTTP {res.status} {res.reason}")
data = res.read().decode()
# Affichage de la réponse
try:
parsed = json.loads(data)
print(json.dumps(parsed, indent=4, ensure_ascii=False))
except json.JSONDecodeError:
print("Réponse :")
print(data)
Consultez la documentation développeur de l’API vStore pour plus de détails sur les fonctionnalités disponibles.
Connexion via Vue au vStore
L’accès aux données du vStore peut également se faire directement à l’aide de vues dans Postgres ou TiDB.
Ces vues peuvent être créées à partir de l’application EDS. Lors de la création d’une vue, une vue distincte est générée pour chaque modèle présent dans votre espace de noms vStore.
Lecture
Vous pouvez utiliser l’exemple suivant pour lire des données depuis une vue Vstore :
- créée à partir de la table laposte
- provenant d’un Vstore EDS nommé mynamespace
- avec un nom d’utilisateur myuser (fourni lors de la création de la vue)
- avec un mot de passe mypassword (fourni lors de la création de la vue)
- avec une URI pgcluster-pooler-rw.shared-sql.svc.cluster.local:5432 (fournie lors de la création de la vue)
pip install sqlalchemy psycopg2-binary
# RÉCUPÉRATION DE DONNÉES DEPUIS LA VUE
from sqlalchemy import create_engine, text
# Ne pas utiliser IAD ici
# Pour PostgreSQl
DATABASE_URL = "postgresql+psycopg2://myuser:mypassword@pgcluster-pooler-rw.shared-sql.svc.cluster.local:5432/mynamespace"
# Pour TiDB
# DATABASE_URL = "mysql+pymysql://myuser:mypassword@pgcluster-pooler-rw.shared-sql.svc.cluster.local:5432/mynamespace"
engine = create_engine(DATABASE_URL)
with engine.connect() as connection:
result = connection.execute(
text('SELECT * FROM "laposte__myuser"')
)
for row in result.mappings():
print(dict(row))
print("--- FIN DES DONNEES ---")
Écriture
Il n’est pas possible d’écrire des données dans un vStore à l’aide des vues. Utilisez une autre méthode pour cela.
Accès aux EdS via TRINO
Cette procédure décrit comment accéder aux Espaces de stockage (EdS) dans Jupyter, via un notebook en utilisant la couche d'abstration trino.
Prérequis
En pré-requis, un administrateur système a créé le catalogue Trino et a donné les accès à l'utilisateur (le compte créé pour l'utilisateur pour le catalogue : user et mot de passe).
Etapes à suivre
Nous allons décrire ci-dessous les étapes pour se connecter à un catalogue Trino via un notebook.
Nous allons utiliser les librairies suivantes :
pip install sqlalchemy-trino==0.5.0 pandas
Nous écrivons le code suivant pour pouvoir désactiver les warnings qu'on reçoit lors de la connexion :
import urllib3
urllib3.disable_warnings()
Après avoir mis en place nos différentes librairies, nous allons réaliser la connexion avec le user déclaré dans Trino (fourni par l'administrateur système).
from sqlalchemy.engine import create_engine
engine = create_engine(f"trino://user:motdepasse@trino.kosmos-data:8443/pgdatscitest1scy?verify=false",)
superset = engine.connect()
Ce code permet de se connecter à Trino avec l'utilisateur user qui a accès au catalogue pgdatscitest1scy, nous pouvons voir l'ensemble des catalogues auxquels il a accès :
import pandas as pd
pd.read_sql("SHOW catalogs", superset)
Le résultat de cette commande est le suivant :
Catalog
0 esdatscitest1scy
1 pgdatscitest1scy
2 pgtest
3 s3datscitest1scy
4 system
Nous allons lister les différents schémas présents dans le catalogue pgdatscitest1scy :
import pandas as pd
pd.read_sql("SHOW schemas in pgdatscitest1scy", superset)
Nous allons lister les différentes tables du schéma "public" du catalogue pgtest :
df = pd.read_sql("SHOW tables in pgtest.public", superset)
Le résultat est le suivant :
print(df)
Table
0 pg_stat_kcache
1 pg_stat_kcache_detail
2 pg_stat_statements
3 t_pilo0_laposte1
Nous allons lire les informations d'une table : tout d'abord nous devons exécuter le code suivant pour pouvoir dire à Trino qu'on va utiliser un schéma et un catalogue :
pd.read_sql("USE pgtest.public", superset)
Nous sélectionnons la table qu'on veut consulter :
df = pd.read_sql("SELECT * FROM t_pilo0_laposte1", superset)
df.head()
Ceci nous donne le résultat suivant :

Utilisation de git
Cette procédure décrit les principales utilisations de gitlab à partir de Jupyter.
La gestion des droits sur les projets gitlab est faite à partir de l'IHM de l'outil par un administrateur (administrateur accès de la zone par exemple).
L'utilisateur métier doit au préalable avoir accédé à Gitlab et s'être créé un token d'accès :
- Procédure standard de gitlab : Editer son profil, se créer un
accesToken.
Cloner un projet gitlab existant
Utilisation via le terminal de Jupyter
A partir du terminal, les commandes gitlab standard sont utilisables.
Attention :
- il faut désactiver le contrôle des certificats : lancer la commande : git config --global http.sslVerify false
Puis, il est nécessaire ici d'utiliser l'accesToken en tant que mot de passe.
Exemple :
jovyan@jupyter-umla--my-50ython:~$ git config --global http.sslVerify false
jovyan@jupyter-umla--my-50ython:~$ git clone https://gitlab.technique.artemis/bas/dbfijupy.git
Cloning into 'dbfijupy'...
Username for 'https://gitlab.technique.artemis': umla
Password for 'https://umla@gitlab.technique.artemis':
remote: Enumerating objects: 34, done.
remote: Total 34 (delta 0), reused 0 (delta 0), pack-reused 34
Unpacking objects: 100% (34/34), 51.14 KiB | 3.41 MiB/s, done.
Changer de serveur
L'utilisateur a la possibilité de choisir un environnement de développement en fonction de son besoin. Cette fonction permet :
- de choisir si les ressources GPU sont nécessaires ;
- de définir la liste des outils et bibliothèques préinstallées avant sa première utilisation.
Cette procédure décrit comment effectuer ces choix.
Étape 1 : Aller dans l'interface du Hub (Hub Control Panel)
- Menu
Homede la page d'accueil
ou bien lorsque l'on est dans un serveur :
- Menu
File->Hub Control Panel
Étape 2 - Stopper puis redémarrer le serveur
Stop My Serverpour arrêter le pod actuel. Ceci arrête le serveur (pod) mais son volume est conservé.Start My Serverpour relancer : le choix de l'image est alors demandé
Une fois le pod démarré, l'IHM bascule automatiquement dans le serveur qui vient de démarrer. Les ressources propres à l'image choisie sont pré-installées.
Accès au jeton OAUTH2 actualisé
Cycle de vie du jeton OAUTH2 dans l'environnement du notebook
Ce schéma explique le cycle de vie des jetons d'accès et d'actualisation OIDC.
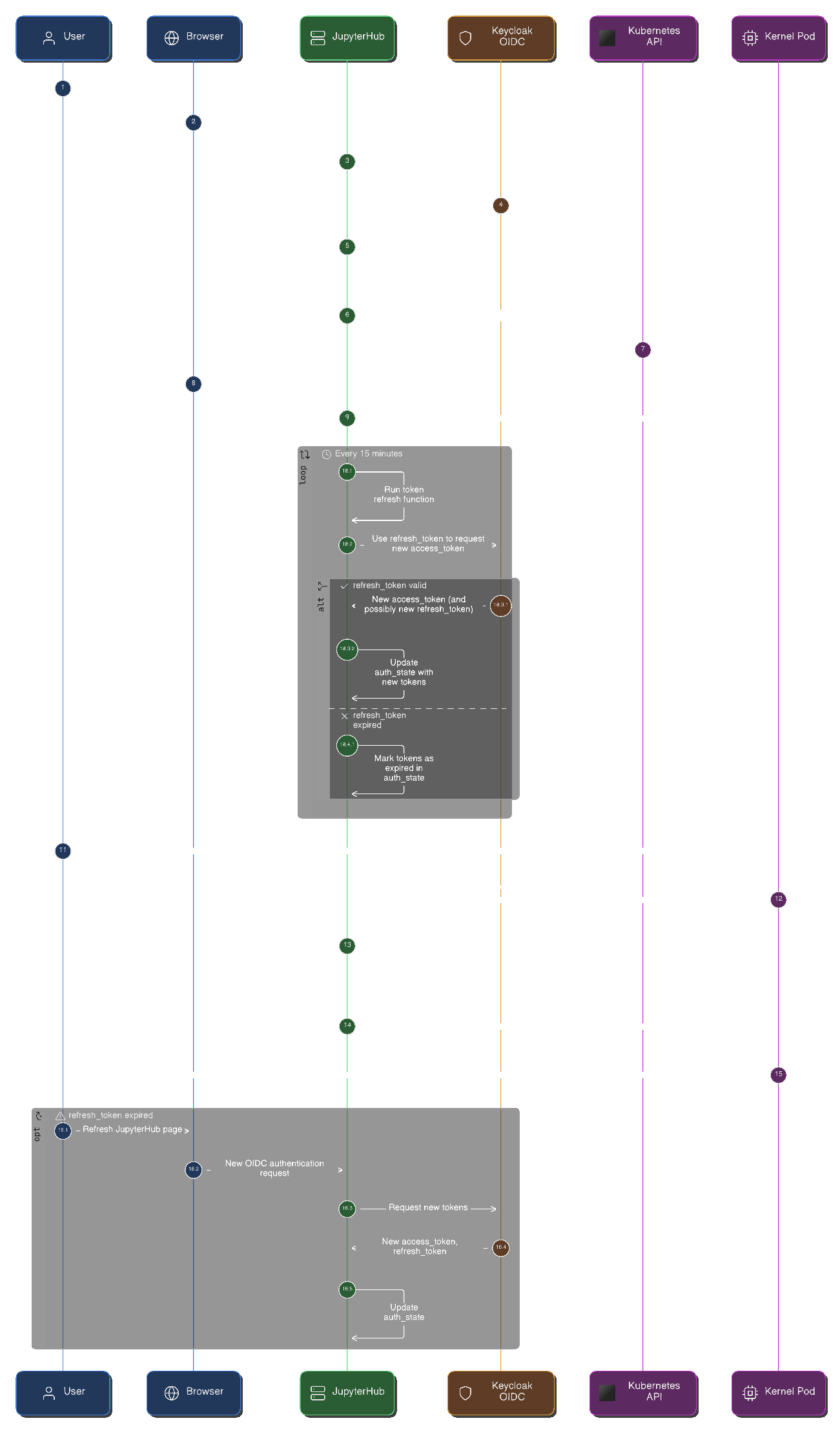
Utilisation du jeton
Lorsqu'un notebook est créé, il possède une variable d'environnement « OAUTH2_ACCESS_TOKEN », qui expire. Dans ce cas, JupyterHub l'actualise si les étendues configurées contiennent « offline_access » et que « auth_refresh_age » est différent de « 0 ». Vous devez ensuite utiliser le code suivant pour obtenir le jeton d'accès valide :
import os
import requests
from jupyterhub.utils import url_path_join
response = requests.get(f"{os.environ['JUPYTERHUB_API_URL']}/users/{os.environ['JUPYTERHUB_USER']}",
headers={'Authorization': f"token {os.environ['JUPYTERHUB_API_TOKEN']}"}
)
new_access_token = response.json()['auth_state']['access_token']
print(new_access_token)
Utilisation des bibliothèques visuelles dans les notebooks
Choisissez le profil « Image de démonstration de visualisation » lors de la création d'un notebook. Ce profil utilise une image contenant les bibliothèques « folium », « tensorboard » et « plotly » ainsi que leurs dépendances pour fonctionner correctement dans un environnement Kubernetes.
Utilisez les cellules suivantes comme exemples d'utilisation de ces bibliothèques :
Folium
import folium
folium.Map(location=(48.866667, 2.333333))
Plotly
from plotly.offline import init_notebook_mode, iplot
from plotly.graph_objs import *
init_notebook_mode(connected=True)
trace0 = Scatter(
x=[1, 2, 3, 4],
y=[10, 15, 13, 17]
)
trace1 = Scatter(
x=[1, 2, 3, 4],
y=[16, 5, 11, 9]
)
iplot([trace0, trace1])
Tensorboard
import tensorboard
import os
%reload_ext tensorboard
%tensorboard --logdir logs