Overview
Le Data Pipeline permet de créer et d'exécuter des Traitements sur les données stockées dans la plateforme. Le terme "Data processing" est souvent utilisé.
L'IHM du Data Pipeline est un outil graphique qui permet à un Utilisateur authentifié de créer un Traitement ou d'importer un Traitement déjà existant. Elle permet également de déployer un Traitement sur la plateforme et de créer le Flux correspondant.
Le Flux est alors exécuté par le moteur du Data Pipeline.
Le moteur du Data Pipeline supporte 2 modes de fonctionnement, Analytique et Basique :
- Le mode Analytique est adapté pour la transformation de données structurées (CSV par exemple) par lot de données (batch) ;
- Le mode Basique est plutôt adapté pour la manipulation de données non structurées (images, PDF,...) au fil de l'eau (streaming).
Le mode Analytique exécute les flux en python par défaut, tandis que le mode Basique les exécute en java par défaut.
Un traitement écrit pour le mode Analytique est constitué d'un enchainement de boites représentant l'entrée des données (les Sources), les transformations qui sont effectuées sur les données (les fonctions) et au bout de la chaîne les sorties des données (les Cibles).
- Un traitement contient au minimum une brique Source et une brique Cible.
- Les boites Sources et Cibles correspondent principalement aux Espaces De Stockage (EdS) de la plateforme.
- Le Data Pipeline est livré avec un jeu de fonctions permettant des transformations élémentaires. Il peut être enrichi grâce à des fonctions personnalisées (User Defined Function ou UDF).
Un traitement écrit pour le mode Basique est constitué d'une ou plusieurs boites opaques reliées entre elles et dans lesquelles s'exécutent des conteneurs personnalisés qui prennent en charge intégralement l'entrée, la transformation et la sortie des données. Ce mode est particulièrement recommandé quand on traite de très gros volumes de données, mais il nécessite de solides compétences en programmation. Il est également pertinent pour effectuer des fonctions complexes (utilisation de GPU, programmes legacy, LLM, Deep Learning, ...).
La documentation du Data Pipeline couvre les thèmes suivants :
- Administration : procédures d'administration et d'exploitation
- Utilisation : aide à l'utilisation de l'IHM
- Développement : guide sur l'écriture de fonctions personnalisées (UDF) pour le mode Analytique et sur le développement de conteneurs personnalisés pour le mode Basique
Environnements
L'IHM du Data Pipeline est accessible via le Portail Métier et permet de déployer les traitements dans les environnements Bac à Sable (BAS), Intégration et Déploiement (EID) et Production (PROD).
Tour d'horizon de l'IHM du Data Pipeline
L'IHM du Data Pipeline expose les vues suivantes pour créer les Traitements et suivre les Flux :
- Supervision : Synthèse des Flux selon leur état (en cours, terminé, erreur, ...)
- Flux : Liste des Flux selon leur état (en cours, terminé, erreur, ...)
- Traitements : Conception et Import des Traitements
- Catalogue de briques : Liste des briques de fonctions de transformation fournies de base ou personnalisées (UDF)
Principales caractéristiques
L'exécution d'un traitement entraine la création d'un flux. Lorsqu'un Flux s'exécute, la plateforme lui alloue des ressources dédiées.
Les flux ne peuvent accéder qu'aux Espaces De Stockage (EdS) métier qui sont éligibles selon les droits sur les objets de la plateforme attribués au profil de l'Utilisateur (politique ABAC). Les paramètres d'accès aux EdS sont déterminés au déploiement du Traitement et restent en vigueur dans le Flux même après que l'Utilisateur ait fermé l'IHM.
Le contrôle du Besoin d'En Connaître (BeC) n'est pas pris en charge à ce jour (itération2). L'accès à un EdS protégé par une politique sera donc systématiquement en erreur.
Diagramme du traitement
En termes de modélisation, le Data Pipeline s'appuie sur un diagramme orienté et acyclique (Directed Acyclic Graph, DAG).
Il débute par une ou plusieurs Sources et chaque branche de Traitements s'achève obligatoirement par une Cible. Dans la majorité des cas, les Sources et les Cibles sont liées à des EdS de la plateforme.
Entre les Sources et les Cibles, les Transformations sont réalisées par des Fonctions basiques ou complexes, que l'utilisateur place dans le diagramme. L'IHM propose de nombreuses Fonctions et la liste peut être étendue via des développements (UDF personnalisées).
Les Sources d'un Traitement se distinguent conceptuellement des Sources externes : ces dernières sont des gisements extérieurs à la plateforme, dont les données sont recopiées dans un EdS. En revanche, cet EdS, que nous nommerons "EdS Source", peut être utilisé en entrée d'un Traitement (à sa Source).
Pour illustrer, une Ingestion de données suivie par un Traitement peut se résumer de la façon suivante :
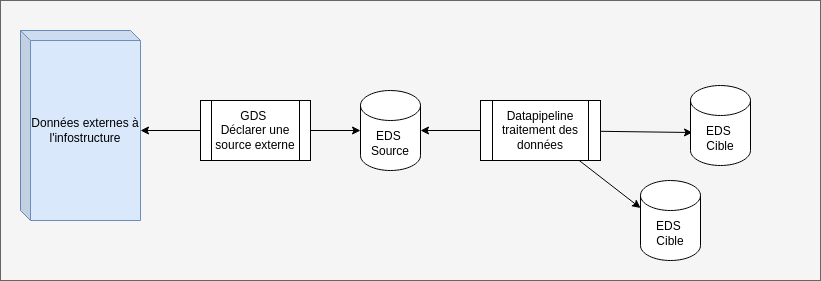
Communément, les Sources, Cibles et Fonctions sont nommées "briques" car elles apparaissent sous forme de rectangles colorés dans l'IHM du Data Pipeline.
Les briques disponibles dépendent du mode utilisé (Analytique ou Basique).
Conseils d'utilisation
Avant de concevoir un traitement, il est recommandé de :
- Obtenir les spécifications des formats des données qui seront manipulées en Entrée et en Sortie.
- Extraire/demander un sous-ensemble de données réduit et représentatif pour la mise au point
- Créer les EdS appropriés
Il est préférable de développer progressivement le traitement dans le Bac-à-sable ou le Kit de Développement Logiciel (KDL), brique après brique, en exécutant le traitement à chaque brique ajoutée.
Politique d'accès aux ressources (ABAC) sur les traitements et briques
Le contrôle ABAC permet à l'utilisateur de voir uniquement les traitements et briques autorisés par la politique sur les traitements et briques. Cette politique est la suivante :
Les règles qui s'appliquent sont, pour les traitements :
- l'organisation du traitement est vide ou fait partie de celles de l'utilisateur (au moins 1)
- l'environnement du traitement est inclus dans ceux de l'utilisateur
et pour les briques :
- l'organisation de la brique est vide ou fait partie de celles de l'utilisateur (au moins 1)
Fonctions (UDF)
Les Fonctions (UDF) implémentent les transformations de données et le routage au sein d'un traitement.
Chaque UDF dispose d'au moins une entrée et d'au moins une sortie.
Pour information, le schéma des données en entrée est automatiquement déduit du schéma de la sortie de l'UDF (ou de la Source) précédente.
Le Data Pipeline propose 4 modes pour implémenter des nouvelles Fonctions :
- Utilisation de l'UDF de "Code in Line"
- Personnalisation d'une UDF existante : en ajoutant un fichier descripteur au format texte YAML, selon les consignes du Guide de Développement
- Développement d'une UDF personnalisée : en codant une bibliothèque Python, selon les consignes du Guide de Développement
- Développement d'un Conteneur personnalisé : en implémentant une image Docker, selon les consignes du Guide de Développement
Version de l'application
La version de l'application peut être consultée sur l'onglet About
