User Guides
Utilisation de Superset
Pour démarrer avec Superset, suivez ces étapes :
Vous pouvez accéder à l'interface utilisateur de Superset via votre « Hub ». Vous serez invité à vous connecter.
Connexion à une source de données
Pour connecter une base de données, accédez à l'onglet « Sources », sélectionnez « Bases de données » et cliquez sur le bouton « Ajouter une base de données ». Choisissez le type de base de données (par exemple, PostgreSQL, MySQL), fournissez les informations d'identification nécessaires et testez la connexion.
N'oubliez pas de cocher les options avancées pour utiliser l'ensemble de données dans SQL Lab
Superset accède aux EdS via leurs connecteurs disponibles, par exemple 'Cickhouse', 'postgresql', ...
Pour le stockage vstore, Superset accède aux EdS via le connecteur 'MySQL'.
Superset permet aussi l'accès aux EdS suivants via Trino en lecture seule (même sur des EdS du Bac à Sable) :
- PostgreSQL
- opensearch
- S3
Dans tous les cas, c'est l'Administrateur de données qui configure la connexion à la database/dataset puis déclare le droit d'accès à cet espace, et enfin il affecte les droits aux utilisateurs métiers. Voir la procédure Superset / Déclarer database & dataset
Créer un tableau de bord
Après avoir connecté votre source de données, accédez à la section « Tableaux de bord » et créez un nouveau tableau de bord. Vous pouvez glisser et déposer différentes visualisations (par exemple, des graphiques, des tableaux) et les configurer à l'aide des données de votre base de données.
Explorez vos données
Utilisez l'onglet « Explorer » pour analyser vos données de manière interactive. Vous pouvez écrire des requêtes SQL ou utiliser l'interface graphique pour créer des visualisations complexes sans écrire de code.
Déclarer les databases et les datasets dans Superset
Cette procédure décrit les actions pour déclarer dans superset les databases et datasets pour qu'un datascientist accéde à un espace de stockage.
Etape 1 - Créer une connexion à une database, puis aux datasets
Accéder au menu Settings > Database Connections :
Cliquer sur le bouton :

Choisir la database :
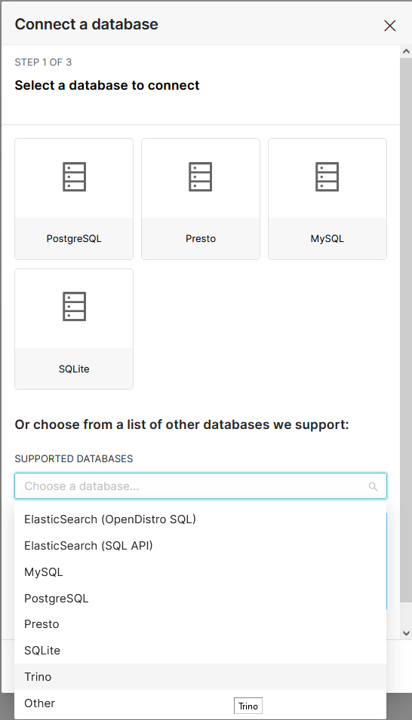
Avec les connecteurs natifs pour les moyens de stockage
Pour les EdS qui disposent de la fonction de génération des compte d'accès, il est possible d'utiliser les connecteurs proposés par Superset (par exemple, postgresql).
1- L'Administrateur données accède à dS pour générer un compte d'accès
2- Il accède à Superset et ajoute la connexion vers la database en utilisant le compte généré (il utilise le compte, le mot de passe et le endpoint). Si l'EDS est protégé par une politique, il ajoute le matricule de l'utilisateur final au compte pour établir la connexion.
Exemple : si EDS fournit un nom d'utilisateur (username) = ivvqsourceprodbec-d3j5qc1s0tvs73a2c7h0-ro alors, si "alice" doit utiliser cet EDS qui est protégé par une politique BEC, l'administrateur données devra utiliser ivvqsourceprodbec-d3j5qc1s0tvs73a2c7h0-ro**_alice** lorsqu'il configure l'accès à la database.
Le port fournit dans le endpoint du compte d'accès créé est celui du protocole natif de clickhouse or le connecteur utilise un protocole HTTP accessible via le port 8123 qui est à remplacer dans l'URL fournie
En utilisant Trino
Pour tous les EDS qui peuvent avoir un catalogue déclaré dans trino, un administrateur système effectue les gestes pour donner accès aux catalogues à l'administrateur de données :
Trino étant configuré avec une authentification, l'administrateur système créé les accès à des catalogues Trino en suivant la procédure du Manuel d'Administration. Il fournit alors à l'administrateur de données les informations d'accès :
- username
- password
- catalogue_name
L'Administrateur données peut alors ajouter une entrée vers le catalogue Trino :
Pour connecter la database au catalogue Trino, on utilise la ligne suivante :
trino://username:password@trino.kosmos-data:8443/catalogue_name?verify=false
Par exemple : à un catalogue PostgreSQL :
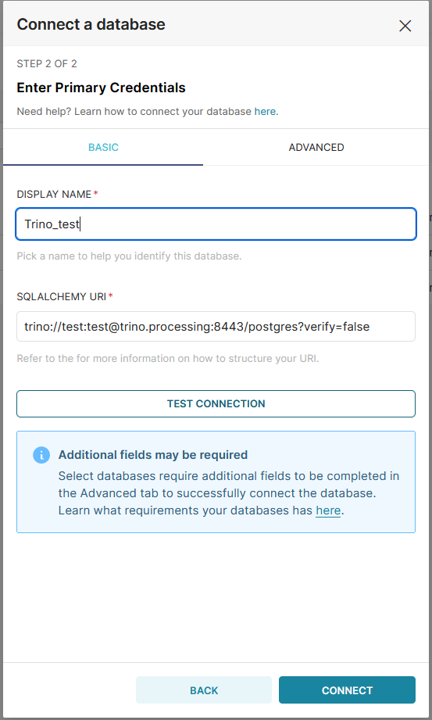
La connexion est maintenant disponible dans la liste des Databases :

Pour vstore : en utilisant la vue vStore
2 étapes : au préalable (étape A) : créer une vue dans vstore en utilisant S-EDS, puis (étape B) Ajouter une entrée (database) vers la vue.
A/ Déclarer la vue dans S-EDS
L'administrateur de données peut administrer les vues, c'est à dire créer des vues pour d'autres personnes ou des vues avec d'autres droits, qui correspondent à d'autres attributs. Pour cela, il utilise l'option "Gérer les vues" dans l'IHM EDS et il coche l'option "Admin" pour saisir les attributs de la vue qu'il créé.
La création de la vue via l'IHM EDS fournit le mot de passe (token) qui doit être utilisé avec ce compte utilisateur (id) pour déclarer (connecter) la database dans superset.
Exemple :
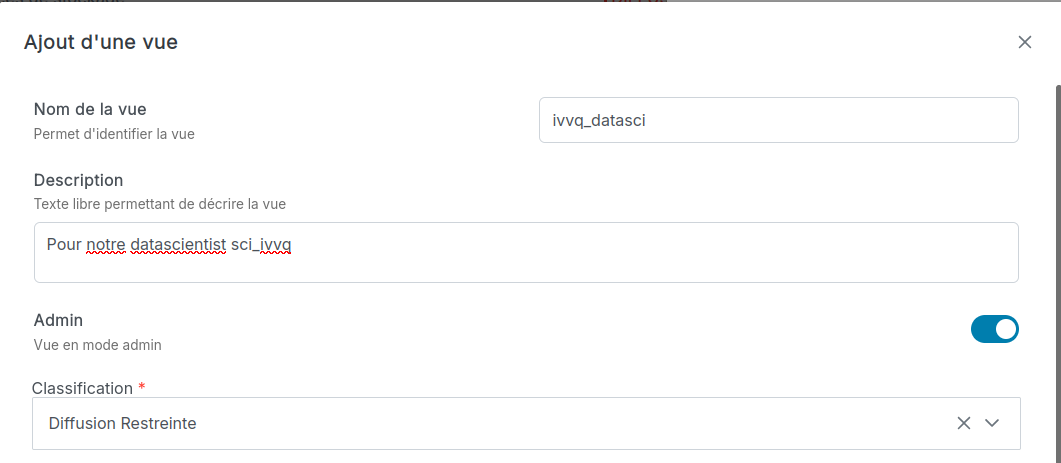
B/ Ajouter une entrée vers la vue créée dans vStore
Dans Superset, l'administrateur de données créé la database pour l'EdS vstore à partir des éléments issus de l'étape A (compte utilisateur et password).
Il crée une nouvelle database de type mysql.
Il renseigne les informations d'accès :
- host:
tidb-vstore-tidb.shared-datavirt-*.svc.cluster.local.* dépend de l'environnement et du backend de ce vstore - port:
4000 - database: nom de l'EdS vStore
- username: celui obtenu lors de la création de la vue
- password: celui obtenu lors de la création de la vue
- display name: nom libre pour l'identification de la database dans superset (en général, nom de l'EdS vStore + de la vue ou de l'utilisateur destinataire).
La connexion est maintenant disponible dans la liste des Databases.
L'Administrateur données doit alors l'affecter à l'utilisateur final (le datascientist) via le rôle.
Créer les Datasets (pour les stockages avec ce niveau de granularité)
Note : pour un espace de stockage ElasticSearch, la création du dataset n'est possible que si le mapping de l'index est défini.
Se rendre dans le menu Data > Datasets :

Cliquer sur le bouton :

Renseigner le formulaire :
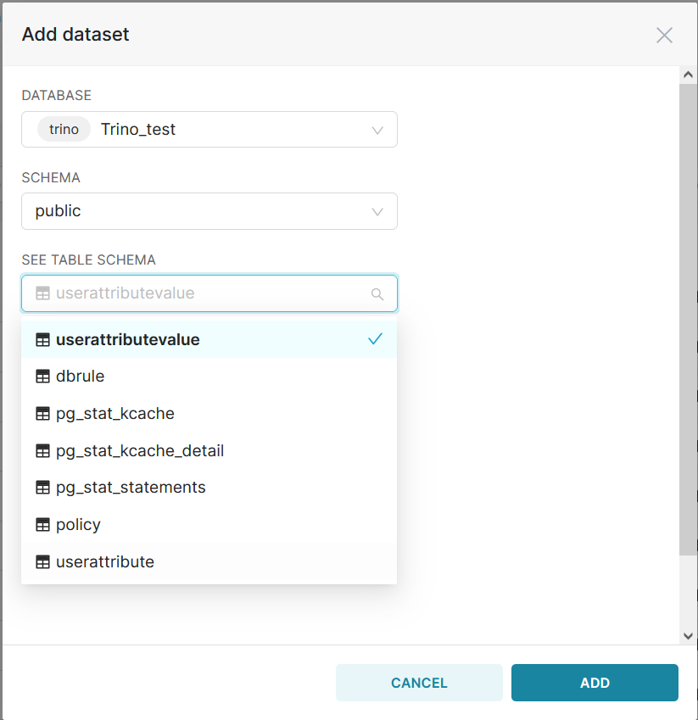
Le dataset est créé et apparait dans l'IHM :

Etape 2 : Donner accès aux utilisateurs
Ajouter un rôle
Pour permettre l'utilisation d'une nouvelle database et de nouveaux datasets, l'administrateur de données doit donner au datascientist les droits nécessaires. Pour cela, se rendre dans le menu Settings > List Roles et ajouter un rôle spécifique pour le datascientist avec le bouton  :
:
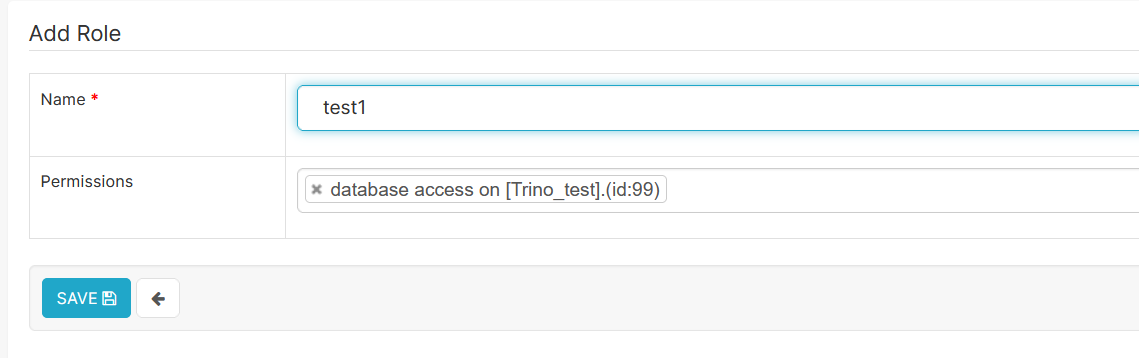
Le champ permission doit contenir les databases et les éventuels datasets auxquels le datascientist aura accès.
Cliquer sur Save.
Affecter un rôle à l'utilisateur
Il faut maintenant affecter ce rôle au datascientist.
Se rendre dans le menu Settings > List Users puis éditer l'utilisateur datascientist souhaité.
Dans le champ rôle, ajouter le rôle définit plus haut :
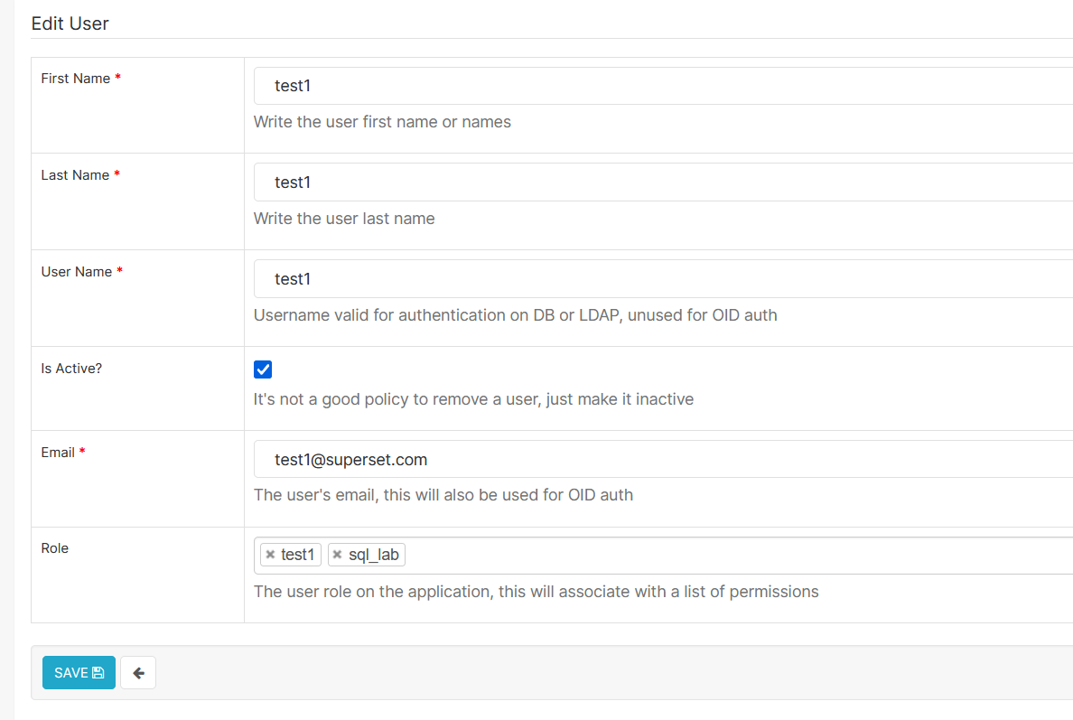
Pour que le datascientist puisse accéder à l'onglet SQL Lab, il faut également lui ajouter le rôle sql_lab.
Rajouter des permissions au rôle
Pour chaque nouveau dataset, il faudra ajouter au rôle du datascientist le droit lié au dataset :
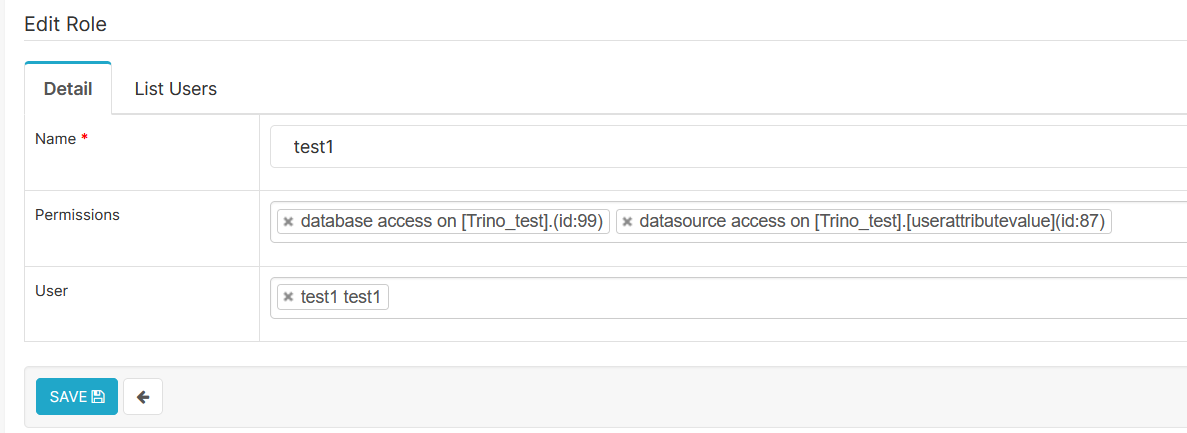
Le datascientist accède alors à Superset et peut utiliser les datasets affectés pour créer ses 'charts' et 'dashboards' : voir la procédure Superset "Explorer les données"
Affichage des tuiles de carte
Superset permet d'afficher des tuiles personnalisées provenant d'un serveur de tuiles vectorielles comme OSM ou Tileserver-GL
- Créer un « Carte graphique », comme « Arc Deck.gl »
- Configurer les colonnes lat et long correspondantes
- Définir l'URL OSM/Tileserver dans l'entrée correspondante
Votre carte devrait s'afficher.
Tileserver-GL est fourni avec des tuiles par défaut.Disponible ici : https://tileserver.mondomaine.artemis/styles/osm-bright/style.json