Development Guides
Créer une fonction personnalisée python pour le moteur analytic
Développer une UDF PySpark
Démarrer un projet Python
Créez un dossier "demo1" pour vos fichiers Python
Créez un fichier "init.py"
Créez un fichier Python dans le dossier avec la fonction suivante :
def tmp_func(iterator): # type: ignore
print("-> tmp_func")
# vous pouvez obtenir le contenu de Dag en utilisant
mymeta: str = meta.get('meta', {}).get('limitforpracma')
for pdf in iterator:
yield pdf
Le nom de la fonction est utilisé lors de l'exécution tout au long de votre DAG.
Générer le fichier dependencies.zip
Pour empaqueter votre code, vous devez créer un fichier zip et le téléverser dans le bucket chargé pendant l'exécution d'un runtime analytique.
Pour construire votre fichier zip, suivez les étapes ci-dessous.
Créez un fichier setup.py :
from setuptools import setup
setup(
name="demo1",
version="1.0.0",
author="KOSMOS-analytics",
description="exemple",
packages=["demo1"],
install_requires=[],
)
Créez un fichier scripts/packages.sh :
#!/usr/bin/env bash
set -o errexit
set -o pipefail
set -a
pwd=$(pwd)
python -m venv venv
venv/bin/pip install -U pip setuptools wheel
venv/bin/pip install .
cd venv/lib/python3.11/site-packages && zip -r dependencies.zip ./* && mv dependencies.zip $pwd/dependencies.zip
trap $(cd $pwd && rm -rf venv)
Créez le Dockerfile :
FROM python:3.11.6-slim AS builder
# Installer les outils
RUN apt-get update &&\
DEBIAN_FRONTEND=noninteractive apt-get install cowsay fortune vim zip wget git make gpg -y
WORKDIR /kast
COPY scripts/ scripts/
COPY demo1/ demo1/ # votre dossier de fichiers Python
COPY setup.py setup.py
RUN scripts/package.sh
FROM scratch AS dependencies
WORKDIR /
COPY --from=builder /kast/dependencies.zip dependencies.zip
Exécutez le Dockerfile :
docker buildx build\
--output=dist\
--target=dependencies . -f Dockerfile
Développer une UDF R
Démarrer un projet R
-
Créez un dossier pour votre projet : exemple1
-
Dans ce dossier, créez un fichier "DESCRIPTION" pour lister vos dépendances :
Package: athea
Title: Script externe de démonstration
Version: 0.0.0.0
Description: Ce que fait le package (un paragraphe).
License: `use_mit_license()`, `use_gpl3_license()` ou amis pour choisir une licence
Encoding: UTF-8
Roxygen: list(markdown = TRUE)
RoxygenNote: 7.3.2
Imports:
data.table (>= 1.9.4),
tidyverse,
lubridate,
nycflights13,
jsonlite,
dplyr,
pracma,
- Créez un fichier NAMESPACE dans le même dossier pour lister les fonctions exportées (à appeler via le DAG) :
export(littleprocess)
export(completeprocess)
- Dans ce dossier, créez un dossier "R" avec un fichier de fonction R à l'intérieur.
Exemple :
# Fonction fournissant les bases pour utiliser un processus R
#' @export
littleprocess <- function(dfs, meta){
print("processus1")
print(meta)
l <- list()
l[[1]] = data.frame(value = c("!!!!!!!!!!!!!!!! Ceci est un texte aléatoire !!!!!!!!!!!!!!"))
for (i in 1:length(dfs)) {
l[i+1] = dfs[i]
}
return(l)
}
# TEST UNITAIRE DU PETIT PROCESSUS
print("Test unitaire du petit processus")
dfeasy1 <- data.frame(value = "triangle")
littlemeta <- data.frame(meta = "{'lang': 'R'")
resultat2 <- littleprocess(dfeasy1, littlemeta)
print(resultat2)
# Fonction montrant comment utiliser un processus R avec des métadonnées et des bibliothèques externes
#' @export
completeprocess <- function(dfs, meta){
# Parser les métadonnées reçues, les métadonnées contiennent toutes les informations dans la propriété "meta." de votre DAG
suppressPackageStartupMessages(library(jsonlite))
meta_string <- meta$meta[1]
# Convertir la chaîne en une liste R
meta_string <- gsub("'", "\"", meta_string)
meta_list <- fromJSON(meta_string)
# Créer une liste pour les résultats
l <- list()
# Pour tous les dataframes reçus
for (i in 1:length(dfs)) {
# Vérifier si c'est un dataframe
if (is.data.frame(dfs[[i]])) {
print(paste("Traitement du dataframe", i))
resultat <- my_function(dfs[[i]], meta_list) # Pour tous les dataframes, appeler votre fonction de transformation
l[[i]] <- resultat
} else {
print(paste("Élément", i, "n'est pas un dataframe"))
}
}
# retourner une liste de dataframes
print("Si l'une des affirmations suivantes n'est pas vraie, vous avez un problème de typage")
print(paste("Devrait être une liste :", typeof(l[[1]])))
print(paste("Devrait être un data.frame :", class(l[[1]])))
print(paste("Devrait être une liste :", typeof(l)))
print(paste("Devrait être une liste :", class(l)))
return(l)
}
# Fonction pour utiliser un algorithme sur un dataframe reçu
my_function <- function(df, meta) {
# importer pracma pour effectuer un logarithme précis sur les petites valeurs
suppressPackageStartupMessages(library(pracma))
# créer une colonne "logarithme" avec la valeur NA
df$logaritm <- NA_real_
# !!! Par défaut, le moteur vous donnera des dataframes avec plus d'une valeur dans chaque dataframe !!!
# pour toutes les valeurs dans votre dataframe
for (i in 1:nrow(df)) {
# meta[["limitforpracma"]] est un paramètre DAG où vous définissez ce qu'est une grande ou une petite valeur
if (df$valeur[i] < meta[["limitforpracma"]]) {
# Utiliser log1p pour les "petites" valeurs
df$logaritm[i] <- log1p(df$valeur[i] - 1)
} else {
# Utiliser log pour les "grandes" valeurs
df$logaritm[i] <- log(df$valeur[i])
}
}
# Retourner le dataframe avec la nouvelle colonne de logarithme
return(df)
}
# TEST UNITAIRE DU PROCESSUS COMPLET
print("Test unitaire du processus complet")
df1 <- data.frame(objet = "triangle", valeur = 0.0000005)
df2 <- data.frame(objet = "cercle", valeur = 0.0001)
df3 <- data.frame(objet = "carré", valeur = 0.002)
combined_df <- rbind(df1, df2)
# Créer une liste de dataframes contenant des dataframes avec une ou deux valeurs
list_of_dfs <- list(combined_df, df3)
# Simuler un objet meta semblable à celui que vous pouvez recevoir
meta <- data.frame(meta = "{'lang': 'R', 'limitforpracma': 0.0001}")
resultat <- completeprocess(list_of_dfs, meta)
print(resultat)
Générer dependencies.zip
Créez un Dockerfile :
FROM registry.localhost:5000/kflow-analytics-runtime-pyspark-r:dev AS builder
ARG ZIP_NAME=dependencies.zip
USER root
RUN apt-get update && apt install -y --no-install-recommends zip libfreetype6-dev libpng-dev libtiff5-dev libjpeg-dev texlive texlive-fonts-extra build-essential liblzma-dev libbz2-dev gfortran make libxml2-dev gcc g++ libssl-dev libcurl4-openssl-dev libfontconfig1-dev libfontconfig-dev libharfbuzz-dev libfribidi-dev &&\
apt autoremove &&\
rm -rf /var/lib/apt/lists/*
USER kosmos
WORKDIR /Rdepsbuilder
RUN mkdir -p /tmp/R
# installer devtools
RUN cat > build.R <<EOF
chooseCRANmirror(graphics=FALSE, ind = 1)
install.packages(c("remotes", "devtools", "usethis"))
EOF
RUN Rscript build.R
# spécifier le chemin via l'argument de construction d'un package source R valide
ARG SRC="exemple1"
COPY ${SRC} ${SRC}
RUN R CMD build ${SRC} &&\
mv ${SRC}_*.tar.gz ${SRC}.tar.gz
# compiler avec les dépendances transitives localement
RUN cat > build.R <<EOF
usrLibs <- Sys.getenv(x = "R_LIBS_USER")
chooseCRANmirror(graphics=FALSE, ind = 1)
library("remotes")
remotes::install_local("${SRC}.tar.gz", lib = usrLibs)
EOF
RUN Rscript build.R
RUN cd /tmp &&\
zip -r $ZIP_NAME R
FROM scratch AS dependencies
WORKDIR /
COPY --from=builder /tmp/$ZIP_NAME $ZIP_NAME
Exécutez-le avec la commande suivante :
docker buildx build\
--output=dist\
--build-arg ZIP_NAME=dependencies.zip \
--target=dependencies . -f Dockerfile
Exemple de DAG
Exemple de DAG utilisant une UDF personnalisée
resources: s3a://extra # bucket avec votre fichier zip d'UDF
dag:
- id: A
type: fs-source
format: csv
topics: test.csv
meta:
delimiter: ","
out:
- B
- id: B
type: map
meta:
limitforpracma: monparametrelibre
# pour R, ajouter meta
# lang: R
name: tmp_func # ou completeprocess pour l'exemple R
fn: from demo1.demo1 import tmp_func
# pour R, fn par défaut est :
#fn |
# library(athea)
# completeprocess <- exemple1::completeprocess
out:
- C
- id: C
type: print
Développer une brique pour le mode Basic
Cette documentation est une base pour expliquer la manière de développer une brique pour le mode basic (équivalent à une UDF pour le mode analytic), développer aussi le YAML pour l'IHM et enfin déployer votre brique sur un DataPipeline.
Nous traiterons ici majoritairement le développement des applications en Python, mais il sera également mentionné la version équivalente du code dans le langage Java pour chaque section.
On retrouve trois étapes majeures à la création d'une nouvelle fonction :
- La création de la fonction via l'écriture du code
- Le packaging et déploiement de la fonction sur un DataPipeline
- La création du Yaml d'IHM
Fonctionnement global
Chaque brique doit avoir un schema Avro.
Car chaque brique prends le schema de la brique pécédante et donne en sortie son schema. C'est grace a ce systeme que les briques "communiquent" entres elles.
Le Schema sortant dépendant du code que la brique produit (voir les exemples ci-dessous).
Le cas simple c'est de prendre le schema de la brique A, le copier coller dans notre brique, et d'ajouter uniquement le champ en plus (voir TP Fil Ropuge), comme ca la brique C a une continuité des informations. ou comme dans l'exemple plus bas on prends le schema de la brique A et on sort un nouveau schema.
Il est possible de poser plusieurs fois sa brique dans l'IHM du datapipeline et de la relier. C'est le principe du concept Producer/Suscriber il peux y avoir N Producer et N Suscriber.
Il est possible de traiter des fichiers physiquement dans sa brique. Il suffit de mettre autodownload a true. (voir exemple ci-dessous)
Autodownload
L'autodownload permet de Télécharger le fichier d'un S3 dans son code, pour l'utiliser directement, comme un fichier physique. Pour que l'autodownload fonctionne bien, il faut obligatoirement dans le schema d'entrée, la clé "key" et "bucket" et "url".
Développement de la fonction
Développement en Python
Afin de pouvoir utiliser le SDK kflow-basic-python-runtime et développer vos fonctions, il vous faut tout d'abord importer le SDK et le rendre utilisable sur votre machine. Pour cela, il suffit d'exécuter les fonctions suivantes:
# extract the dependencies from the runtime image
cat > Dockerfile.kf-basicpy-dist <<EOF
FROM kflow-basic-python-runtime:dev AS runtime
FROM scratch AS dependencies
COPY --from=runtime /usr/app/kfbasicpy.tar.gz .
EOF
docker buildx build --output=dist --target=dependencies . -f Dockerfile.kf-basicpy-dist
rm Dockerfile.kf-basicpy-dist
# make APIs visible to IDEs
## install essential
pip install dist/kfbasicpy.tar.gz
## install with ner dependencies
pip install "dist/kfbasicpy.tar.gz[ner]"
## install with ner and extract dependencies
pip install "dist/kfbasicpy.tar.gz[ner,extract]"
Une variante possible pour installer le SDK est de l'importer sur votre machine, créer une archive tar.gz comprenant le dossier kfbasicpy ainsi que le pyproject.toml. Enfin, executer la commande pip install votre_archive.tar.gz
Une fois cela fait, vous pourrez importer et utiliser les éléments nécessaires pour réaliser vos fonctions pour le runtime basic en Python.
Pour créer votre fonction, il vous faudra créer deux fichiers qui contiendront respectivement le Main de votre fonction et le code à executer.
Commencons par le fichier du code à executer: il faut y créer une classe implémentant l'interface ProcessFunction, ce qui offre toutes les fonctions afin de réaliser votre programme. Détaillons un peu l'utilisation de chaque fonction proposée par l'interface:
-
La fonction
open(self, ctx: OpenContext)est appelée au début de l'éxecution de la fonction et sert en général à l'initialisation de variables, config et autres éléments à initialiser au début de la fonction. leOpenContextqui est contenu dans les paramètres contient trois fonctions:get_metaqui permet de récupérer la configuration indiquée par le champ "meta" dans le Pipeline. C'est ainsi qu'on peut récupérer des paramètres passés par l'utilisateur et les utiliser ensuite dans la fonction.upload(self: Self, file_name: str, bucket: str, key: str, **kwargs: str) -> boolPermet d'upload un document vers un S3download(self: Self, bucket: str, key: str) -> DownloadResultPermet de télécharger un document depuis S3 et de récupérer son chemin local
-
process(self, event_dict: dict[str, Any], ctx: Context)est quant à elle appelée pour chaque entrée qui est passé à la fonction. Plusieurs élément lui sont passés en paramètres:event_dictqui est un dictionnaire correspondant au données en entrée de la fonction.- le Context qui permet de récupérer plusieurs éléments en relation avec le fichier qui est téléchargé automatiquement, nottament le chemin local et les métadonnées via
get_downloader_local_object_urletget_property.
Dans l'optique ou vous souhaitez retourner de la donnée vers un output avec votre fonction, il suffit de retourner les entrées comme un Array de dictionnaire ou un dictionnaire simple.
Voici un rapide bout de code afin d'illustrer l'utilisation de tous ces éléments dans la fonction Process:
import logging
from typing import Any
from kfbasicpy.function.context import Context
from kfbasicpy.function.function import ProcessFunction
from kfbasicpy.function.open_context import OpenContext
from kfbasicpy.runtime.basic import BasicRuntime
import csv
logger = logging.getLogger(__name__)
class ProcessCSVFunction(ProcessFunction):
"""
Used avro Schema
schema: |
{
"namespace": "myns",
"type": "record",
"name": "myname",
"fields": [
{"name": "a", "type": "string"},
{"name": "b", "type": "string"}
]
}
"""
def open(self, ctx: OpenContext) -> None:
"""called once on startup"""
logger.info("opened")
def process(self, event_dict: dict[str, Any], ctx: Context) -> dict[str, Any] | list[dict[str, Any]]:
"""process an input event
- The received dict abides to the schema defined in the previous task
- The output dict should abides to the schema defined in either the
- process function task
- or the next function receiving this process function result as input.
in this example, the dict expects to contain as output two fields named
url(type=string) and size(type=long)
"""
logger.info(f"event = {event_dict}, context = {ctx}")
fileToProcessLocalPath = ctx.get_downloader_local_object_url()
eventList: list[dict[str, Any]] = list()
with open(fileToProcessLocalPath, newline='') as csvFile:
reader = csv.reader(csvFile, delimiter=',')
for row in reader:
eventList.append({"a": row[0], "b": row[1]}) # obviously, some error handling should be added here
return eventList
def close(self):
"""
close function useful for resources cleaning, etc.
"""
pass
- Enfin, la fonction
close(self)est appelé en dernier et peut servir à libérer des ressources, fermer des têtes de lecture ou d'ecritude, etc ...
Une fois votre fonction réalisée, vous devrez l'affecter au runtime Basic via le Main. Pour cela, il suffira de créer un Main comme ci-dessous:
from kfbasicpy.runtime.basic import BasicRuntime
from kfbasicpy.function.forward_function import ForwardProcessFunction
from kfbasicpy.function.print_function import PrintProcessFunction
from kfbasicpy.function.txtextract_function import TxtExtractFunction
from os import getenv
from function.process_csv import ProcessCSVFunction
if __name__ == "__main__":
import logging
import sys
logging.basicConfig(
format='[%(name)s]: (%(asctime)s) => %(message)s',
datefmt='%m/%d/%Y %I:%M:%S %p',
level=logging.getLevelName(getenv("KFLOW_RUNTIME_LOG_LEVEL", "INFO")),
stream=sys.stdout
)
runtime = BasicRuntime()
runtime.add_process_function(VotreFonction())
runtime.run()
Développement en Java
Dans le cas ou vous souhaitez développer votre fonction en Java, il vous faudra tout d'abord créer un projet Java Maven et ajouter la dépendance vers le kflow-basic-java-runtime:
<dependency>
<groupId>tech.athea.kosmos</groupId>
<artifactId>kflow-basic-java-runtime</artifactId>
<version>{version}</version>
</dependency>
et ne pas oublié pour la compilation d'utiliser le plugin maven "shade" (toujours dans le pom).
...
<plugin>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Main-Class>mon.super.package.MyMain</Main-Class>
</manifestEntries>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
</transformers>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
</execution>
</executions>
</plugin>
...
Vous pourrez alors créer deux fichiers source java: le Main ainsi que le fichier contenant le code de votre fonction.
Commençons par voir le code de notre fonction. La classe qui sera contenu dedans devra implémenter l'interface ProcessFunction qui offre toutes les fonctions et structures pour réaliser notre programme.
L'interface ProcessFunction se présente sous la forme suivante:
open(String, OpenContext)qui s'exécute au lancement du code et qui sera utile nottament pour instancier les clients nécessaires au bon fonctionnement de la fonction. Le string passé en paramètre est le schéma Avro des données en entrées, tandis que le OpenContext est composé de l'objet Meta qui contient les métadonnées passées par l'IHM de la fonction, ainsi que le KFlowBlobHandler permettant de réaliser des lectures et écritures sur S3. Il faut noter que ce dernier élément est null dans le cas ou le paramètre autoDownload est défini à False.invoke(GenericData.Record, Context)est quant à lui appelé à chaque entrée du fichier lu par la fonction. GenericData.Record correspond à la donnée en entrée, tandis que le Context est composé du chemin local du fichier qui à été téléchargé automatiquement, les métadonnées du fichier, une méthode pour demander une validation manuelle des inputs, et enfin la fonctionflush(Path)pour supprimer un fichier présent au chemin indiqué. C'est donc dansinvokeque vous réaliserez le coeur de votre fonction.schemaIn()permet de récupérer le schéma avro des données passées en entrée dans le cas ou ce n'est pas directement fourni dans le pipeline. Il faut noter que cette fonction s'éxecute en premier, avant mêmeopen.schemaOut()n'est pas utilisée pour le moment, mais elle doit retourner le schéma des données retournées.close()est appelé à la fin de l'execution de la fonction, cela permet entre autres de fermer proprement les differents clients instanciés lors duopen
Voici un exemple d'application afin d'illustrer l'utilisation du SDK Java:
package mon.super.package.demo;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import org.apache.avro.Schema;
import org.apache.avro.SchemaBuilder;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericData.Record;
import de.siegmar.fastcsv.reader.CommentStrategy;
import de.siegmar.fastcsv.reader.CsvReader;
import de.siegmar.fastcsv.reader.CsvRecord;
import tech.athea.kosmos.function.Context;
import tech.athea.kosmos.function.OpenContext;
import tech.athea.kosmos.function.ProcessFunction;
public class ProcessCSVFunction implements ProcessFunction {
private Schema schema = null;
/**
* Call one time at start.
*
* Usefull to initialize resources or other (db connection, etc...)
*
* @param schemaIn The avro string schema of input message (could be null)
* @param ctx A context that can contain optional configuration, handlers
* to manipulate blob file, etc...
*/
@Override
public void open(final String schemaIn, final OpenContext ctx) throws Exception {
this.schema = SchemaBuilder.record("myname")
.namespace("myns")
.fields()
.requiredString("a")
.requiredString("b")
.endRecord();
};
/**
* Call for each msg batch.
*
* @param record The in record
* @param ctx An optional context that can contain optional configurations,
* handlers, etc...
* @return A records batch to forward
*/
@Override
public Record[] invoke(Record record, Context ctx) throws Exception {
// Get file to process from context if autodownload requested
final String fileToProcessLocalPath = ctx.getDownloaderLocalObjectUrl();
// Select only the two first column
final File f = new File(fileToProcessLocalPath);
final List<GenericData.Record> outRecords = new ArrayList<>();
try (final CsvReader<CsvRecord> csv = CsvReader.builder().commentStrategy(CommentStrategy.SKIP)
.ofCsvRecord(f.toPath())) {
csv.forEach(new Consumer<CsvRecord>() {
@Override
public void accept(CsvRecord csvRec) {
final GenericData.Record outRecord = new GenericData.Record(schema);
outRecord.put("a", csvRec.getField(0));
outRecord.put("b", csvRec.getField(1));
outRecords.add(outRecord);
}
});
}
return outRecords.toArray(new GenericData.Record[0]);
}
@Override
public String schemaOut() {
return this.schema.toString();
}
}
Le schema a utiliser en entrée :
{
"namespace": "myns",
"type": "record",
"name": "myname",
"fields": [
{"name": "a", "type": "string"},
{"name": "b", "type": "string"}
]
}
Un autre type d'exemple et comment récuperer les fields du schémas d'entrée :
public class ExtractPDF
[...]
public void open(String schemaIn, OpenContext ctx) throws Exception {
this.schema = createOutSchema();
}
private Schema createOutSchema() {
String schema = """
{
"type": "record",
"name": "record",
"fields": [
{
"name": "url",
"type": "string"
},
{
"name": "lastModifiedUnixMilli",
"type": "long"
},
{
"name": "bucket",
"type": "string"
},
{
"name": "key",
"type": "string"
},
{"name": "pdfcontent", "type": [ "null", "string" ]}
]
}
""";
return new Schema.Parser().parse(schema);
}
public GenericData.Record[] invoke(GenericData.Record record, Context ctx) throws Exception {
[...]
//code pour pouvoir récuperer les anciennes clés (de "url" a "key") et de remplir la nouvelle ("pdfcontent").
//toutes les clés de "url a "key" viennent par exemple de la brique "source s3"
//pdfcontent = un text extrait d'un pdf.
String s3url = (String) record.get("url");
Long s3lastModif = (Long) record.get("lastModifiedUnixMilli");
String s3bucket = (String) record.get("bucket");
String s3Key = (String) record.get("key");
String text = getTextPDF(); //la methode n'existe pas dans l'exemple.
GenericData.Record result = new GenericRecordBuilder(schema)
.set("url", s3url)
.set("lastModifiedUnixMilli", s3lastModif)
.set("bucket", s3bucket)
.set("key", s3Key)
.set("pdfcontent", text)
.build();
return new GenericData.Record[]{result};
}
@Override
public String schemaOut() {
return this.schema.toString();
}
[...]
Une fois que vous avez développé votre fonction, vous devez aller dans le Main et y appeler votre fonction afin qu'elle soit utilisable par le runtime. Cela prend la forme suivante:
package mon.super.package;
import tech.athea.function.ProcessCSVFunction;
import tech.athea.kosmos.runtime.BasicJavaRuntime;
public class MyMain {
public static void main(final String[] args) throws Exception {
final BasicJavaRuntime runtime = new BasicJavaRuntime();
runtime.addProcessFunction(new ExtractPDF());
runtime.run();
}
}
Packaging et déploiement sur une plateforme
Une fois la fonction créée, il est nécessaire de la packager avant de l'envoyer vers une plateforme quelconque.
Pour créer l'archive avec les dépendances (ou FatJar pour les fonctions en Java) il faut utiliser un dockerfile qui va aller récupérer toutes les dépendances nécessaires au fonctionnement de la fonction et les archiver dans un dossier. Voici le dockerfile à utiliser, avec une variante dans le cas ou on utilise Python et une autre dans le cas ou on utilise java:
# ---------- Dockerfile pour PYTHON ----------
ARG PYTHON_RUNTIME_VERSION="3.11.7-slim"
FROM python:${PYTHON_RUNTIME_VERSION} AS builder
RUN pip install -U pip setuptools wheel build
WORKDIR /kosmos
COPY kfbasicpy/ kfbasicpy/
COPY pyproject.toml pyproject.toml
COPY LICENSE.txt LICENSE.txt
COPY README.md README.md
RUN python -m build . &&\
mv dist/kfbasicpy-*.tar.gz dist/kfbasicpy.tar.gz
FROM python:${PYTHON_RUNTIME_VERSION}
ARG USERNAME="kosmos"
RUN groupadd --gid 1000 ${USERNAME}\
&& useradd --uid 1000 --gid 1000 -m ${USERNAME}
USER ${USERNAME}
RUN pip install -U pip setuptools wheel
WORKDIR /usr/app
COPY /kosmos/dist/kfbasicpy.tar.gz kfbasicpy.tar.gz
RUN pip install kfbasicpy.tar.gz
COPY topology.yaml /usr/app/topology/topology.yaml
COPY main.py /usr/app/main.py
ENV PYTHONUNBUFFERED=1
ENTRYPOINT [ "python", "main.py" ]
# ---------- Dockerfile pour JAVA ----------
FROM hosted-registry.technique.artemis/maven:3.9.6-eclipse-temurin-17 as builder
COPY src /usr/src/app/src
COPY pom.xml /usr/src/app
RUN mvn -f /usr/src/app/pom.xml clean package
FROM hosted-registry.technique.artemis/eclipse-temurin:17
COPY /usr/src/app/src/main/resources/*.xml /usr/app/
COPY /usr/src/app/target/monUberJar.jar /usr/app/monUberJar.jar
USER root
RUN groupadd kosmos
RUN useradd -g kosmos kosmos
USER kosmos
ENTRYPOINT ["java", "-XX:MaxRAMPercentage=80.0", "-Dlog4j.configurationFile=file:///usr/app/log4j2.xml", "-cp", "/usr/app/monUberJar.jar", "mon.super.package.MyMain"]
Il faut ensuite lancer ce dockerfile avec les commandes ci-dessous qui permettent également de définir le nom de la fonction, sa version ainsi que le registry.
# Define ENV Variables
export IMAGE_NAME=basic-func
export IMAGE_TAG=v1
export REGISTRY=hosted-registry.technique.artemis
# Docker Build
sudo docker build -t $REGISTRY/$IMAGE_NAME:$IMAGE_TAG .
# Docker Save
sudo docker save $REGISTRY/$IMAGE_NAME:$IMAGE_TAG > $IMAGE_NAME-$IMAGE_TAG.tar
Une fois l'archive générée, vous pouvez la déployer sur une plateforme afin de la rendre disponible aux utilisateurs.
Cela se fait en deux temps: il faut tout d'abord envoyer l'archive sur la machine visée.
# depuis le poste de travail
export IMAGE_DIR=/data
export SPRAY=[config ssh cible]
scp $IMAGE_NAME-$IMAGE_TAG.tar $SPRAY:$IMAGE_DIR
ssh -t $SPRAY 'cd $IMAGE_DIR && ls -lh $IMAGE_NAME-$IMAGE_TAG.tar ; bash'
Une fois cela fait, il faut ouvrir un tunnel SSH vers la machine visée et réaliser l'installation avec les commandes suivantes.
# depuis la machine SPRAY
export IMAGE_DIR=$(dirname $PWD)
export IMAGE_NAME="my-basic-func"
export IMAGE_TAG="v1"
export REGISTRY="hosted-registry.technique.artemis"
# load & push des images
docker load < $IMAGE_DIR/$IMAGE_NAME-$IMAGE_TAG.tar
docker push $REGISTRY/$IMAGE_NAME:$IMAGE_TAG
L'installation peut être réalisée également au moyen de la commande kosmos import selon la procédure suivante :
Créer le fichier descripteur_my-basic-func.yml contenant la structure de l'archive à importer.
items:
- type: container
resource: /my-basic-func:v1
Créer l'arborescence de l'archive à importer.
| descripteur_my-basic-func.yml
|-container
| |- my-basic-func-v1.tar
Créer le zip my-basic-func-v1.zip de l'arborescence de l'archive.
Passer la commande d'import :
kosmos import my-basic-func-v1.zip
Il est évidemment nécessaire d'adapter le nom de l'image, le tag et le registry selon ce que vous souhaitez déployer.
Développement du YAML d'IHM
Afin d'utiliser la fonction il est nécessaire d'avoir un YAML décrivant l'IHM proposée à l'utilisateur qui souhaite intégrer la fonction dans une topologie. Ce Yaml doit entre autre renseigner le nom de l'image générée ainsi que tous les paramètres nécessaires au bon fonctionnement de l'image. On peut se baser sur le Yaml décrit ci-dessous :
L'exemple fournit est un exemple "avancé" (un showroom).
---
name: Nom_Fonction
type: raw
kind: function
runtimeMode: basic
description: |
description de la fonction
tabs:
- name: Général
fields: [ image, imagePullPolicy, schema, globalConfig.store.addr, globalConfig.store.user, globalConfig.store.password, globalConfig.store.autoDownload, globalConfig.metrics.enabled ]
- name: Avancé
fields: [ meta.container.cpuLimit, meta.container.memoryLimit, meta.container.cpuRequest, meta.container.cpuRequest, meta.container.memoryRequest, meta.container.env ]
settings:
image:
name: Image
type: string
default_value: hosted-registry.technique.artemis/Nom_Fonction:v1
help: Image pour la fonction Nom_Fonction
required: true
imagePullPolicy:
name: Politique d'extraction d'images
type: choice[IfNotPresent;Always;Never]
default_value: Always
help: configuration de l'image
required: false
globalConfig.store.addr:
name: Adresse
type: string
required: true
globalConfig.store.user:
name: Utilisateur
type: string
required: true
globalConfig.store.password:
name: Mot de passe
type: password
required: true
globalConfig.store.autoDownload:
name: Auto Téléchargement
type: boolean
default_value: true
required: true
globalConfig.metrics.enabled:
name: Autoriser les métriques
type: boolean
default_value: false
required: false
schema:
name: Schema
type: code[json]
required: false
default_value: '{"type":"record",
"name":"ActivityTransformFlow",
"namespace":"tech.athea.datasic.model",
"fields":[
{"name":"activityTask","type":["null","string"]},
{"name":"duration","type":{"type":"double","java-class":"java.lang.Double"}},
{"name":"exitStatus","type":{"type":"int","java-class":"java.lang.Integer"}},
{"name":"jobName","type":["null","string"]},
{"name":"jobType","type":["null","string"]}
]
}'
help: |-
Veuillez saisir le schéma de vos données
[...]
input:
- name: entrée
output:
- name: main
Image, Adresse, User et password sont obligatoires a écrire et a remplir (soit dans le yml ou dans l'interface).
Pour avoir une documentation complète sur la création des Yaml pour les briques, voir documentation création Yaml IHM
Ajout d’une fonction au catalogue
Importer de nouvelles briques
Pour importer une brique se rapporter à la procédure “Gérer les briques” dans la partie “service_donnees/Datapipeline” du dtu-utilisation. L’ajout d’une brique nécessite un fichier YAML de description que vous pouvez créer en vous appuyant sur la documentation ci-dessous.
Logique générale des YAML d’IHM
Le but principal d’un YAML d’IHM est de produire une boîte du DAG. Le DAG pour Directed acyclic graph (Graphe acyclique dirigé en Français) est le liant entre le moteur temporal se trouvant derrière l’IHM Datapipeline-ui et les images Docker Basic Runtime ou les UDF qui vont effectuer les traitements dans l’image Docker du Analytic Runtime.
Pour construire des UDF Analytic Runtime ou des images Docker Basic Runtime vous pouvez vous reporter aux documentations correspondantes :
- pour une brique Analytic Runtime Python
- pour une brique Analytic Runtime R
- pour une brique Basic Runtime
Une bonne pratique pour développer une brique est de la programmer pour qu’elle utilise les paramètres d’entrée décrits dans la partie du DAG liée à la brique. Une fois ce travail fait la suite de cette documentation explique les différentes options pour permettre aux utilisateurs de la brique de renseigner les paramètres d’entrée.
L’option onlyMyUdf en mode analytique
Si l'administrateur a activé l’option “onlyMyUdf” qui est désactivée pour défaut alors vous pourrez ajouter dans vos fichiers YAML un champ “code” au même niveau que le name ou le type.
Ce champ précise le bucket du S3 technique ainsi que le nom du fichier ZIP contenant le code créé dans le cadre d’une UDF personnalisée analytique runtime.
Exemple
name: Replace
type: query
code: bucket1/dependenciesA.zip
Cette option permet, dans une plateforme avec beaucoup de code personnalisé, de ne charger dans le pod qui démarre que le code dont il a besoin et pas celui de toutes les briques. Cela permet de meilleures performances ainsi que de gérer des conflits entre différentes versions de librairies qui pourraient être embarquées dans différents fichiers zip.
Si l’option est active, mais que cette balise n’est pas renseignée, alors aucun code personnalisé ne sera chargé au démarrage du traitement. A contrario, le contenu de cette balise sera ignoré si l’option n’est pas activée.
En-tete du fichier YAML
L’entête du fichier YAML est composée de 5 propriétés:
namequi est le nom qui apparaît dans l’IHMtypequi peut prendre les valeursraw,query,map,fs-source,print,fs-sink,jdbc-source,kafka-sink,elastic-sink,s3-sink, etc…. Elles seront dans 99% de 3 types:rawpour les briquesBasic Runtimequerypour les briquesAnalytic Runtimecontenant des requêtes SQLmappour les briquesAnalytic Runtimecontenant des fonctions Python
kindqui peut prendre les valeurssource,sinkoufunctioncorrespondant à l’onglet de la palette où est rangée la brique (utiliserfunctiondans 99% des cas, il faut des développements très spécifiques pour créer unesourceou unsink)descriptionqui contient des informations sur la brique. Elles seront consultables depuis l’ongletdocumentationde la brique quand elle est ajoutée dans le traitementruntimeModequi est pour le choix du moteur. il y a deux possibilitées:basicanalytic

Exemple d’entête de fichier :
name: S3 Csv
type: fs-source
kind: source
icon: fichier.svg # voir documentation "ajout icones briques"
runtimeMode: basic
description: |-
Liste les fichiers périodiquement depuis un répertoire (S3).
Relier votre brique à son icône
Dans le fichier de description du YAML d'IHM (voir documentation "ajout_catalogue de ce même DTU). Ajoutez une propriété "icons" contenant le nom de votre icône au même niveau que les propriété "name" et "type".
name: Source S3 With EdS
type: fs-source
icon: fichier.svg
Le nom du fichier ne doit pas contenir d'espace, de caractères spéciaux, ni de majuscule. Les fichiers de type icône doivent :
-
respecter le format :
[fichier_sans_extension_ou_accent].svg -
le format doit être compatible
SVG+HTML. -
ne pas être dans des tons de couleur bleu/rouge ou vert car il s'agit des couleurs de fond pour chacune des catégories (source, fonction, cible)
Exemple de format compatible :
<svg width="24" height="24" viewBox="0 0 24 24" xmlns="http://www.w3.org/2000/svg">
<path d="M8.604 2c.572 0 1.125.204 1.563.577l.141.131L12 4.4h9.6c1.265 0 2.31.992 2.394 2.236L24 6.8v12c0 1.265-.992 2.31-2.236 2.394l-.164.006H2.4a2.408 2.408 0 0 1-2.394-2.236L0 18.8.012 4.4c0-1.265.98-2.31 2.224-2.394L2.4 2h6.204zm5.474 5h-.963c-.629 0-1.152.523-1.113 1.152a9.46 9.46 0 0 0 8.845 8.846c.63.039 1.153-.484 1.153-1.113v-.963a1.103 1.103 0 0 0-.98-1.103l-1.414-.161a1.11 1.11 0 0 0-.913.317L17.669 15A8.374 8.374 0 0 1 14 11.331l1.03-1.03c.239-.24.355-.573.317-.913l-.161-1.403A1.115 1.115 0 0 0 14.078 7zM9.5 10h-7l-.117.007a1 1 0 0 0 0 1.986L2.5 12h7l.117-.007A1 1 0 0 0 9.5 10zm0-3.5h-7l-.117.007a1 1 0 0 0 0 1.986L2.5 8.5h7l.117-.007A1 1 0 0 0 9.5 6.5z" fill="#1E2122" fill-rule="evenodd"/>
</svg>
Si aucun icône n'est choisit dans un YAML d'IHM, l'icône représentant un dossier sera mis par défaut.
Liste des champs pour chaque onglet
Le YAML d’IHM est ensuite composé d’une clé appelée tabs. Cette clé permet de définir quel champ se trouve dans quel onglet lorsqu'on clique sur une brique.
La liste des champs présents dans les différents onglets doit correspondre strictement à la liste des champs décrits dans le chapitre Inventaire du champ type dans la partie settings.
Exemple
tabs:
- name: Général
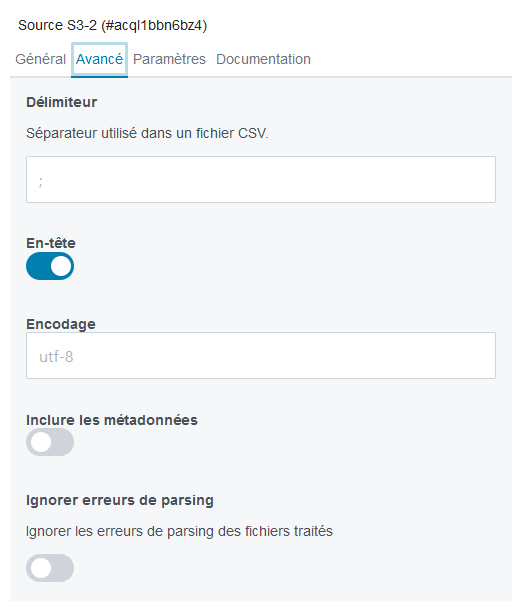
fields: [ topics, format, addr, user, password, viewSQL, asTable, schema ]
- name: Avancé
fields: [ meta.delimiter, meta.header, meta.encoding, meta.includeFileMetadata, meta.ignore-parse-errors ]
Description des champs
La partie suivante décrit les champs disponibles. Il est possible pour chaque champ de proposer de nombreuses options.
Pour écrire une clé champ il faut d’abord écrire son nom, qui doit correspondre au nom attendu dans le DAG ainsi qu’au nom présent dans le tableau fields de la partie tabs.
Exemple :
settings:
topics:
name: URL du répertoire S3
type: string
Dans les noms, l’élément ”.” correspond à une indentation.
Exemple:
meta.ki.cible:
name: Répertoire S3
type: string
s’affichera de la façon suivante, dans le dag:
{
"meta": {
"ki": {
"cible": "nom_du_repertoire"
}
}
}
Si l’on ne veut pas qu’un élément soit indenté, il faut l’entourer de crochets.
Exemple :
meta.[ki.cible]:
name: Répertoire S3
type: string
s’affichera de la façon suivante, dans le dag:
{
"meta": {
"ki.cible": "nom_du_repertoire"
}
}
Les champs contenant des échappements d’indentation doivent être entourés de guillemets dans les listes de fields :
tabs:
- name: Avancé
fields: [ "meta.[bulk.enabled]" ]
Inventaire du champ type dans la partie settings
La première option, obligatoire, est le champ type qui permet d’indiquer à l’UI le type de champ à afficher à l’utilisateur. Il en existe plusieurs types :
text: Objet de typeTextArea, sera de typeStringdans le DAG

string: Objet de typeTextField, sera de typeStringdans le DAG

number: Objet de typeTextField, sera de typeIntegerouDouble(c’est à dire sans guillements) dans le DAG.

number[A;B]: Objet de typeSlideravec A comme valeur minimum et B comme valeur maximum, ne gère que les entiers.- Si
B < Aon ne pourra choisir avec le Slider que les valeurs A ou B. Aucune valeur intermédiaire ne sera disponible
- Si

boolean: Object de typeSwitch, sera de typebooleandans le DAG.

booleanstring: Permet d’afficher unSwitchqui prendra soit la valeur “true” ou “false” mais qui retournera l’élément sous forme de string dans le DAG

choice[A;B;C]: Objet de typeDropdownListproposant les choix A, B ou C. Le type seraStringdans le DAG.

multichoice[A;B;C]: Objet de typeDropdownListavec possibilité de choisir zéro ou plusieurs éléments entre A, B et/ou C. Cet élément permet de créer un tableau d’éléments de typestringdans le DAG, par exemple["URL_a","URL_b"]

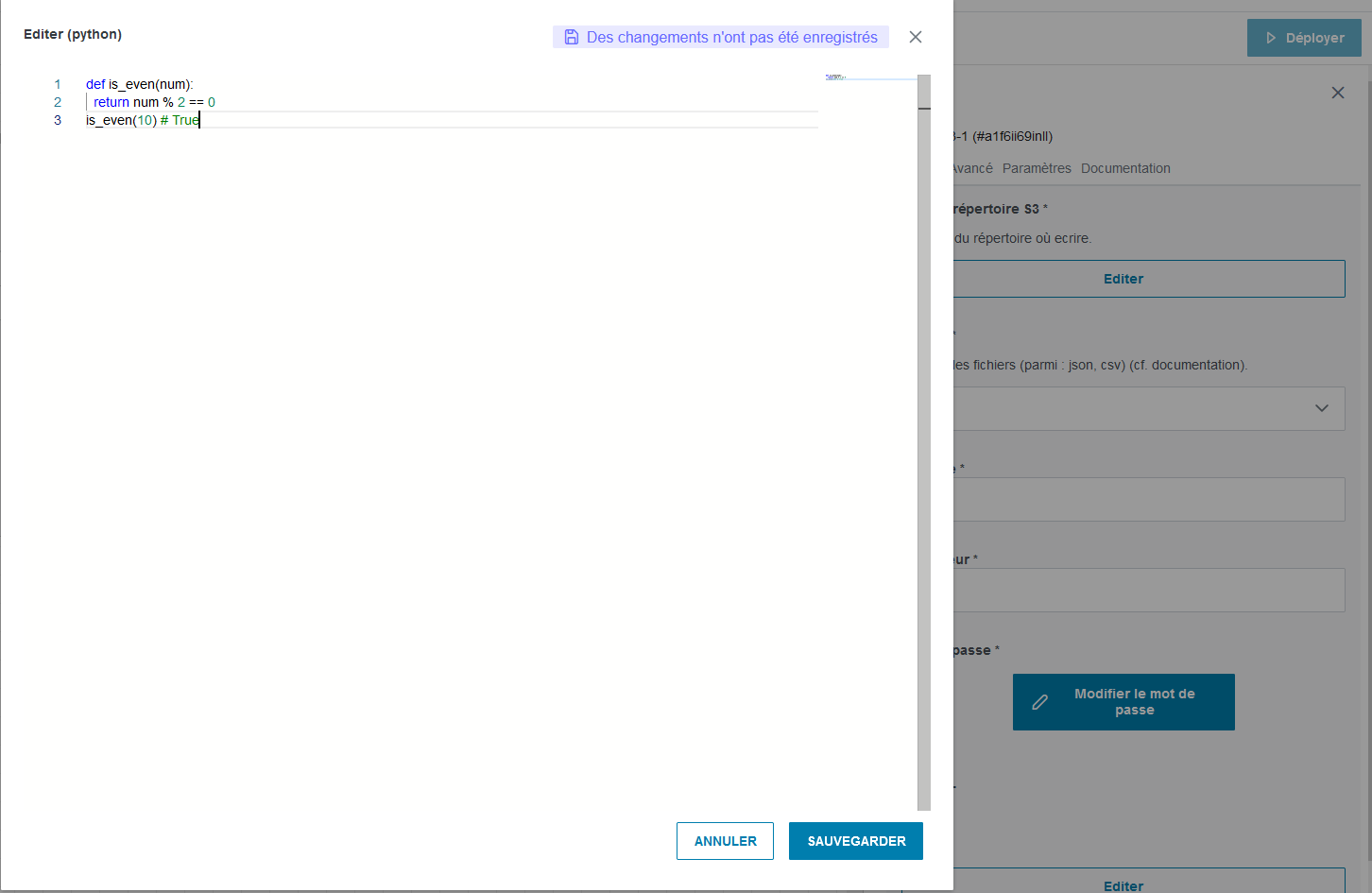
code[**language**]: Objet de typetextAreaavec support pour la colorisation et l’IntelliSense pour le language indiqué.**language**peut prendre l’une des valeurs suivantes: typescript, javascript, css, less, scss, json, html, xml, php, c#, c++, razor, markdown, diff, java, vb, coffeescript, handlebars, batch, pug, f#, lua, powershell, python, ruby, sass, r, objective-c
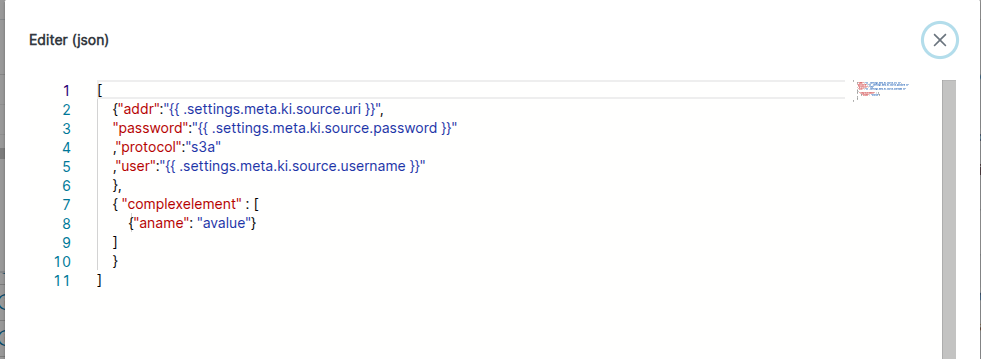
codeparsed: Objet de type textArea avec support de colorisation et d’IntelliSense. Le language utilisé dans ce widget est le JSON.
Ce widget permet d'insérer un JSON non monoliné directement dans votre DAG.
Il permet de gérer facilement des types avec des imbrications à plusieurs niveau comme par exemple un map d'array. Mais en contrepartie l'utilisateur doit écrire lui même un JSON valide.
Ce widget est souvent utilisé pour l'ajout de sidecars à vos containers.
Exemple de déclaration avec valeur par défaut
meta.download:
name: Informations de Téléchargement
type: codeparsed
default_value:
- protocol: s3a
addr: "{{ .settings.meta.ki.source.uri }}"
user: "{{ .settings.meta.ki.source.username }}"
password: "{{ .settings.meta.ki.source.password }}"
Exemple de valeur modifiée:
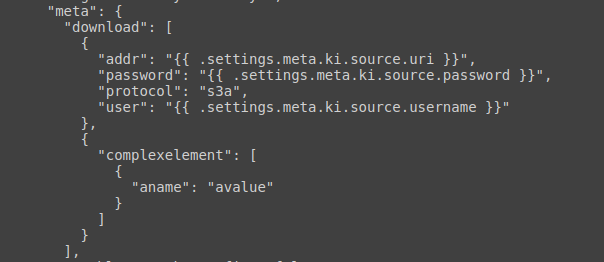
Résultat dans le DAG:
-
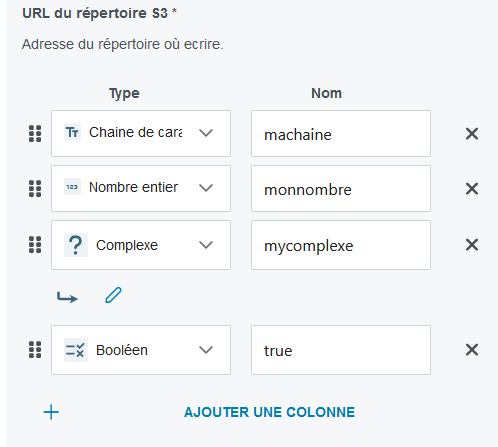
avro: Objet de typeSchéma Avroavec support pour l’édition du schéma avro, sera de typeStringdans le DAG.- Si on souhaite avoir un sous schéma dans avro, choisir le type
complexe, et il faudra renseigner le type complexe dans une boîte de code - L’exemple en capture d’écran donnera un champ dans le DAG qui ressemble à
"topics": "{\"type\":\"record\",\"name\":\"document\",\"fields\":[{\"name\":\"machaine\",\"type\":\"string\"},{\"name\":\"monnombre\",\"type\":\"int\"},{\"name\":\"mycomplexe\",\"type\":{\"toto\":\"tata\"}},{\"name\":\"true\",\"type\":\"boolean\"}]}", - Si on souhaite avoir un sous schéma dans avro, choisir le type
password: Permet de saisir un champ avec l’interface dédiée auxmots de passe, avec le masquage de la saisie de l’utilisateur.
-
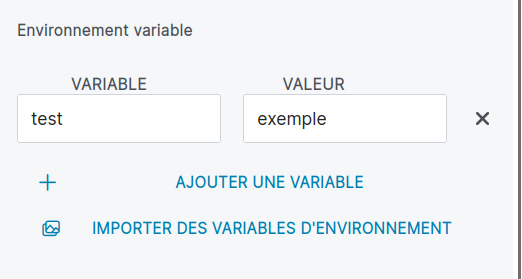
keyValues: Permet d’afficher une interface qui elle même permet de gérer untableau de clés/valeurs. La valeur de retour sera untableau de deux strings.- Exemple de
default valuepour un keyValues:
- Exemple de
default_value:
- name: KFLOW_FUNC
value: print
- Exemple d’un élément créé dans le DAG:
"topics": [
{
"name": "test",
"value": "exemple"
}
],
- ce widget permet également d’importer des données en masse. Pour celà cliquer sur le bouton “Importer des variables d’environnement”. L’extension du fichier importé doit obligatoirement être : ”.properties”. Chaque ligne du fichier doit respecter le format suivant : “clé=valeur”. Attention il n’est pas possible de dupliquer une clé.
-
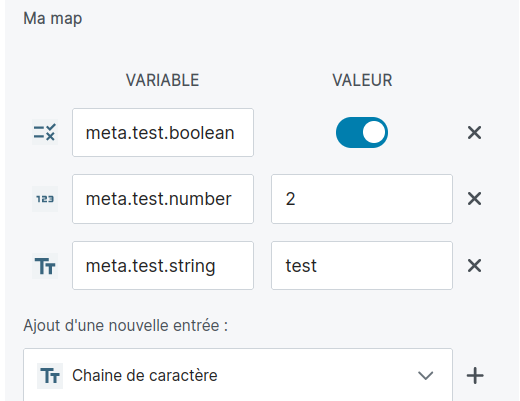
map: Permet d’afficher une interface qui elle même permet de gérer unobjet de clés/valeurs. Les clés sont forcément de type string, les valeurs peuvent être de type : string, number ou boolean.- Exemple de
default valuepour un map:
- Exemple de
default_value:
meta.test.number: 2
meta.test.boolean: true
meta.test.string: "test"
- Exemple d’un élément créé dans le DAG:
"env": {
"meta.test.boolean": true,
"meta.test.number": 2,
"meta.test.string": "test"
}
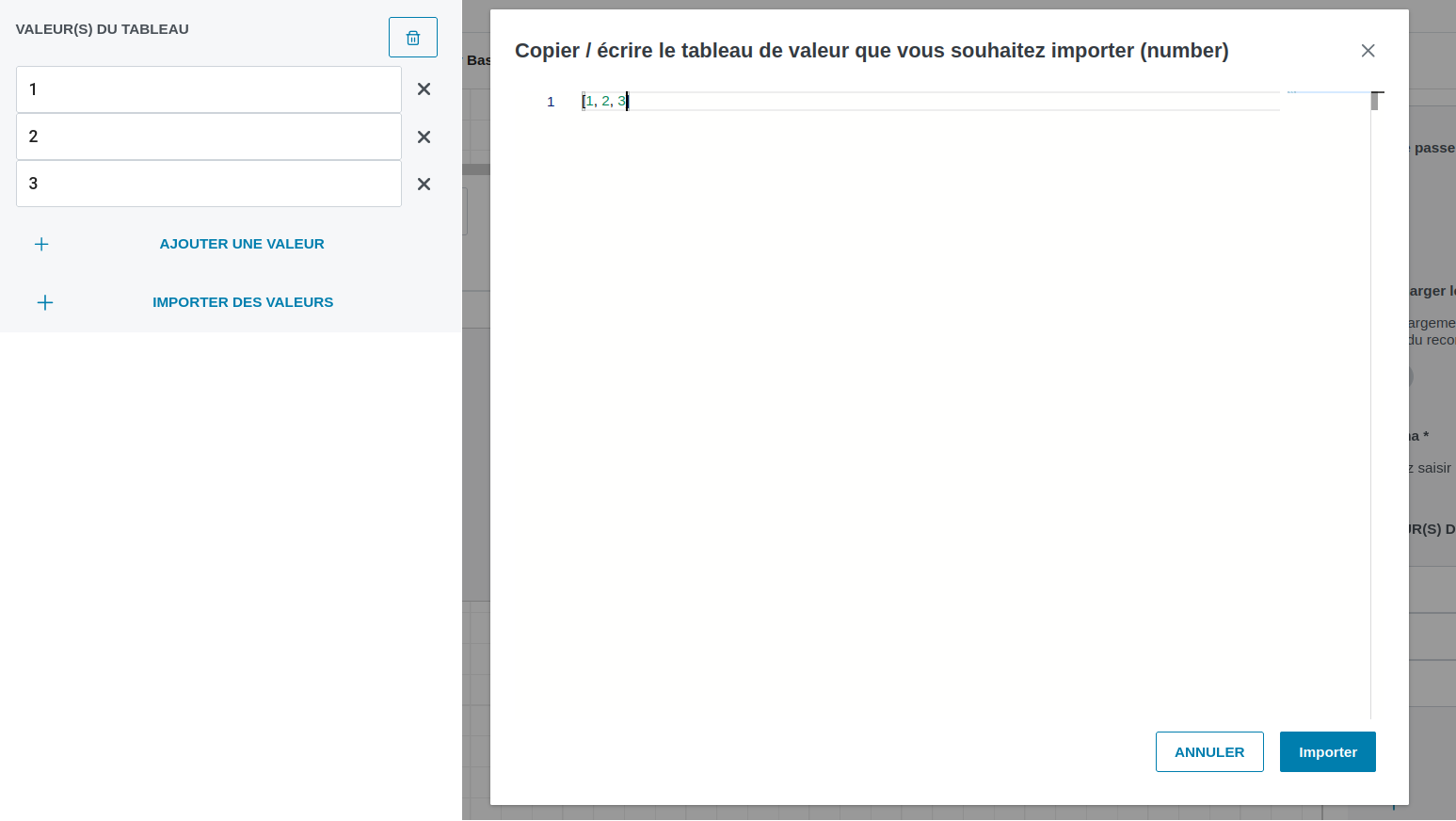
array: Permet de gérer untableau simple de valeurs. Ces valeurs sont par défaut de typestring. Mais on peut, en associant untype_paramavec la valeur number, éditer des valeurs uniquement de typenumber, avec tous les contrôles de surface nécessaires. Ce widget permet également d’importer des valeurs en masse.
Exemple de déclarations et de DAG associés:
# avec la déclaration
test:
name: testarray
type: array
required: false
# on obtient, après ajout de valeur dans le dag
"test": [
"toto1",
"toto"
],
# avec la déclaration
test:
name: testarray
type: array
type_param: number
required: false
# on obtient, après ajout de valeur dans le dag
"test": [
2,
1
],
edsChoice: Permet de sélectionner, parmi une liste d’espaces de stockagedisponibles sur la plateforme. Permet notamment d’éviter de saisir toutes les informations de connexion d’un Espace De Stockage (EdS). En précisant untype_param(voir ci-dessous), on peut filtrer sur le type d’EdS qu’on veut remonter.

Le fonctionnement des EdS dans le DAG
Les types d’EdS possibles (type_param) sont s3, pures3, kafka, rdbm, jdbc,vstore ou es
Pour mettre un EdS dans le YAML d’IHM, il faut créer un élément dont le nom est: “meta.ki.{nomKI}”, cet élément ne doit pas être hidden Exemple :
meta.ki.cible:
name: Répertoire S3
type: edsChoice
type_param: s3
Le fait de mettre un champ de ce type donne accès à de nouveaux remplacements, qui seront effectués côté backend de datapipeline-ui pour des raisons de confidentialité des mots de passe
Pour les différents types, les remplacements disponibles sont :
-
Pour s3 et pures3
- bucketName
- region
- uri
- username
- password
- scheme
-
Pour rdbm ou jdbc
- uri
- database
- username
- password
-
Pour kafka
- uri
- topics
- groupId
- username
- password
-
Pour vstore
- hostname
- namespace
- port
- uri
-
Pour es
- uri
- indexBasename
- username
- password
- protocol
Les variables disponibles sont au format {{ .settings.meta.ki.{'nomKI'}.{remplacement} }}
Exemple : {{ .settings.meta.ki.cible.bucketname }}
Voici un exemple complet d’utilisation d’un EdS. Ce qu’il faut comprendre de cet exemple est :
- j’ai un boolean
meta.advanced_modequi permet de jouer sur des conditions - je déclare une liste de sélection d’un EdS
- je crée une variable permettant de donner manuellement un mot de passe
- je crée un champ caché qui prendra, selon la valeur du boolean
meta.advanced_modesoit la valeur du mot de passe passée à la main (qui ne sera pas présente deux fois dans le DAG grâce à la propriété no_render) soit la valeur{{ .settings.meta.ki.cible.password }}qui sera remplacée au moment de l’exécution
settings:
meta.advanced_mode:
name: Mode avancé
type: boolean
required: true
default_value: false
meta.ki.cible:
name: Répertoire S3
type: edsChoice
type_param: s3
help: Sélectionner un espace de stockage
required: true
condition:
keyName: 'meta.advanced_mode'
values:
- false
manualpassword:
name: URL du répertoire S3
type: string
default_value: s3a://bucket/dir
no_render: true
help: "Adresse du répertoire (ou du fichier) à lire. Si l'adresse est un répertoire, l'intégralité du dossier sera lue. format 's3a://bucket/key'"
required: true
condition:
keyName: 'meta.advanced_mode'
values:
- true
password:
name: Mot de passe
type: password
required: true
dependencies:
- keyName: 'meta.advanced_mode'
values:
- value: false
replace_value: '{{ .settings.meta.ki.cible.password }}'
- value: true
replace_value: '${manualpassword}'
Configuration des clefs settings
Chaque champ, en plus de son type possède un certain nombre de clefs de configuration:
name: Nom qui sera affiché dans l’UI à côté du champ.help: Indication affichée à l’utilisateur pour faciliter le remplissage des champs.default_value: Valeur par défaut du champ. Tant que le champ est vide cette valeur sera prise, il n’est pas possible d’avoir une valeur vide lorsqu’une valeur par défaut non vide a été configurée. Pour les champs suivants : number, choice, code, text, multichoice, avro, array et keyValues, il faut savoir que si la syntaxe de ladefault valuen’est pas correcte l’ui ne l’affiche pas et alerte l’utilisateur avec le message suivant au niveau du widget concerné : “La valeur par défaut est incorrecte, veuillez la corriger ou saisir une valeur afin de l’écraser”.placeholder: Texte qui s’affiche en grisé dans un input, quand on commence à saisir une valeur dans le champ, la valeur du placeholder disparaît. Le placeholder ne crée pas de valeur par défaut dans le DAGrequired: Indique si le champ est à remplir obligatoirement pour permettre un lancement de traitement.hidden: Indique si le champ doit être affiché dans l’interface. Celui-ci sera néanmoins présent dans le DAG.no_render: Indique si le champ doit être présent dans le DAG. Celui-ci sera néanmoins présent dans l’interface. Le plus souvent un champno_renderest présent pour afficher une information à l’utilisateur ou pour servir dans une interpollationdisabled: Indique si le champ doit être impossible à modifier ou non. Celui-ci sera néanmoins toujours présent dans l’interface et le DAG.type_param: permet de qualifier un type. Sa fonction dépend du type auquel ce champ est associé. Par exemple, si le type estedsChoice, on peut alors préciser le type d’EdS qu’on veut afficher via ce paramètre. Par exemple on peut utiliser la valeurkafkapour ne récupérer que des EdS de type kafka.inference: Peut prendre les valeurs true ou false. Utilisation possible sur les champs de type string. Permet d’activer sur ce champ l’option d’inférence, qui est une option qui permet de choisir par autocomplétion un champ défini dans le schéma avro d’une boîte précédente du traitement et ainsi d’utiliser une variable définie contenue dans les données comme élément du DAG. L’exemple le plus commun est de définir par les données le nom du bucket ou de la table SQL où doivent être déposées des données.dependencies: permet de spécifier des dépendances entre le champ courant et d’autres champs. Par exemple, on peut vouloir modifier la valeur du champ courant en fonction de la valeur d’un autre champ. Supporte également les placeholders dans les valeurs de retour. Voir l’exemple ci-dessous.condition: permet d’indiquer si le champ est à prendre en compte ou non en fonction de la valeur d’un autre champ.condition est composée de 2 clés :- keyName, qui est la valeur du champ surveillé
- values, la ou les valeurs du champ surveillé pour lesquelles ce champ s’affichera
Exemple d’utilisation de la propriété condition :
---
[...]
format:
name: Choisir le format
type: choice[raw;json;csv;list]
required: true
default_value: csv
meta.port:
name: port
type: string
condition:
keyName: 'format'
values:
- 'csv'
- 'json'
[...]
Dans l’exemple ci-dessus le champ port sera visible si le champ format vaut json ou csv
Exemple d’utilisation du champ dependencies :
---
[...]
addr:
name: Service Kafka
type: string
required: true
hidden: true
dependencies:
- keyName: 'meta.advanced_mode'
values:
- value: false
replace_value: '{{ .settings.meta.ki.cible.uri }}'
- value: true
replace_value: '${kafkahost}'
[...]
Dans l’exemple ci-dessus le champ addr, qui est un champ masqué, prendra une des valeurs '{{ .settings.meta.ki.cible.uri }}' ou '${kafkahost}' en fonction de la valeur du champ meta.advanced_mode. Pour être plus précis, la valeur de addr sera '{{ .settings.meta.ki.cible.uri }}' si le champ meta.advanced_mode a la valeur false (attention le type est respecté, par exemple 'false' est considérée différente de false) et à l’inverse, la valeur deviendra '${kafkahost}' si la valeur de meta.advanced_mode est true. Plusieurs valeurs sont possibles. A noter que dans l’exemple, dans le cas d’une valeur true, la valeur finale du champ addr sera remplacée par la valeur du champ kafkahost. Toute valeur qui est entre ${} sera interpolée.
Exemple de default_value pour un champ de type keyValues
meta.container.env:
name: Environnement variable
type: keyValues
required: false
default_value:
- name: KFLOW_FUNC
value: print
La valeur stockée dans la default value s’ajoute au DAG et au widget dans l’UI.
Interpolation
Il est possible de référencer la valeur d’un champ dans un autre en utilisant de l’interpolation. Cette interpolation est faite en entourant le chemin complet de la clef YAML par ${}.
Voici un exemple utilisant cette technique afin de décomposer un champ url en 2 champs différents à demander à l’utilisateur, le hostname et le port sans pour autant mettre ceux-ci dans le DAG grâce à la clef no_render.
---
[...]
meta.hostname:
name: hostname
type: string
help: hostname
no_render: true
required: true
hidden: false
meta.port:
name: port
type: string
help: port number
no_render: true
required: true
hidden: false
meta.url:
name: url
type: string
help: Bucket dans lequel le fichier doit être créé.
required: true
hidden: false
default_value: "${meta.hostname}:${meta.port}"
[...]
Output
La dernier partie du fichier décrit la sortie de la boîte dans un champ output.
Pour le moment cette partie ne sert qu’à afficher le nom de la sortie dans datapipeline-ui.
L'option MessageStore
En mode basic, par défaut toute brique de fonction qui veut transmettre des events (messages entre les briques) trop volumineux (par défaut nats est configuré pour une taille de messsage maximale à 1Mo) fera transiter les messages par S3.
Vous pouvez ajouter sur vos briques fonction l'option:
globalConfig.messageStore.enabled:
name: Message Store
type: boolean
help: Utiliser S3 pour les messages volumineux
default_value: true
Cela permettra aux utilisateur de votre brique de refuser l'utilisation de S3 en cas de message volumineux. Des messages trop volumineux peuvent en effet selon votre cas d'usage signifier des erreurs ou une mauvaise utilisation de votre composant.
Si vous voulez que sur votre brique cette option soit désactivée par défaut et non disponible au changement par l'utilisateur:
globalConfig.messageStore.enabled:
name: Message Store
type: boolean
default_value: true
hidden: true
Exemple de fichier complet
name: Requête
runtimeMode: basic
type: query
kind: function
runtimeMode: basic
description: |
Filtre SQL
tabs:
- name: Général
fields: [ sql ]
settings:
sql:
type: code[sql]
required: true
input:
- name: entrée
output:
- name: main
name: Forward
runtimeMode: basic
type: raw
kind: function
description: |
Fait suivre à la boîte suivante
tabs:
- name: Général
fields: [ image, imagePullPolicy, schema ]
settings:
image:
name: Image
type: string
default_value: hosted-registry.technique.artemis/kflow-runtime-java:v3.1
help: Image utilisée pour la brique "Forward"
required: true
hidden: true
imagePullPolicy:
name: Politique d'extraction d'images
type: choice[IfNotPresent;Always;Never]
default_value: Always
help: configuration de l'image
required: true
schema:
name: Schema
type: code[json]
required: true
help: |-
Veuillez saisir le schéma de vos données
input:
- name: entrée
output:
- name: main
name: Source S3 With EdS
runtimeMode: basic
type: fs-source
kind: source
icon: fichier.svg # voir documentation "ajout icones briques"
description: |-
Lire des fichiers depuis un répertoire (S3) au format sélectionné.
tabs:
- name: Général
fields: [ meta.advanced_mode, meta.ki.cible, urls3, pathInBucket, topics, format, addr, user, password, viewSQL, asTable, schema ]
- name: Avancé
fields: [ meta.delimiter, meta.csvHeader, meta.encoding, meta.includeFileMetadata, meta.ignore-parse-errors ]
settings:
meta.advanced_mode:
name: Mode avancé
type: boolean
required: true
default_value: false
meta.ki.cible:
name: Répertoire S3
type: edsChoice
type_param: s3
help: Sélectionner un espace de stockage
required: true
condition:
keyName: 'meta.advanced_mode'
values:
- false
urls3:
name: URL du répertoire S3
type: string
default_value: s3a://bucket/dir
no_render: true
help: "Adresse du répertoire (ou du fichier) à lire. Si l'adresse est un répertoire, l'intégralité du dossier sera lue. format 's3a://bucket/key'"
required: true
condition:
keyName: 'meta.advanced_mode'
values:
- true
pathInBucket:
name: Chemin dans le bucket
type: string
default_value: "path/file.txt"
no_render: true
required: false
condition:
keyName: 'meta.advanced_mode'
values:
- false
topics:
name: URL du répertoire S3 en mode EdS
type: string
required: true
hidden: true
dependencies:
- keyName: 'meta.advanced_mode'
values:
- value: false
replace_value: 's3a://{{ .settings.meta.ki.cible.bucketname }}/${pathInBucket}'
- value: true
replace_value: '${urls3}'
format:
name: Format
type: choice[json;csv]
required: true
default_value: csv
help: 'Format des fichiers (parmi : json, csv) (cf. documentation).'
addr:
name: Adresse
type: string
required: true
user:
name: Utilisateur
type: string
required: true
password:
name: Mot de passe
type: password
required: true
viewSQL:
name: Vue SQL
type: boolean
default_value: classic
required: false
no_render: true
asTable:
name: ID de la vue SQL
type: string
condition:
keyName: 'viewSQL'
values:
- true
## Csv
meta.delimiter:
name: Délimiteur
type: string
required: false
default_value: ";"
help: Séparateur utilisé dans un fichier CSV.
condition:
keyName: 'format'
values:
- 'csv'
meta.csvHeader:
name: En-tête
type: boolean
required: false
default_value: true
condition:
keyName: 'format'
values:
- 'csv'
meta.encoding:
name: Encodage
type: string
required: false
default_value: 'utf-8'
condition:
keyName: 'format'
values:
- 'csv'
meta.includeFileMetadata:
name: Inclure les métadonnées
type: boolean
required: false
default_value: false
condition:
keyName: 'format'
values:
- 'csv'
meta.ignore-parse-errors:
name: Ignorer erreurs de parsing
type: booleanstring
required: false
default_value: false
help: Ignorer les erreurs de parsing des fichiers traités
condition:
keyName: 'format'
values:
- 'csv'
schema:
name: Schéma
type: code[string]
required: false
output:
- name: main
Activation du mode GPU
Pour que votre brique soit exécutée sur un noeud kubernetes avec du GPU, il faut renseigner les champs suivant dans votre YAML d'IHM:
meta.container.gpuRequest:
name: Requête GPU
type: number
default_value: 1
required: false
meta.container.gpuLimit:
name: Limite GPU
type: number
default_value: 1
required: false
Au niveau de votre YAML d'IHM et de votre traitement aucune autre modification n'est à faire.
Il vous faut cependant :
- un programme utilisant du GPU (le plus souvent une image docker BasicRuntime avec du code CUDA)
- Une plateforme Kubernetes avec du GPU physique disponible ainsi que les pré-requis d'utilisation GPU Athea sur Kubernetes présent (pour celà rapprochez vous des administrateurs de la plateforme)
Utilisation de templating Sprig
L'utilisation du moteur de template Golang sprig en version 3.2.2 est possible dans votre DAG.
Celui ci peut permettre de gérer diverses choses comme des condition, des valeurs par défaut sur les variable EdS, etc...
Pour la documentation complète des fonctionnalités disponibles : https://masterminds.github.io/sprig/
Exemple d'utilisation:
- dans mon DAG j'ai la propriété
{{ printf `%s://%s` .settings.meta.ki.cible.scheme .settings.meta.ki.cible.uri | trimPrefix `http://` | trimPrefix `://` }}
- résultat attendu :
- ma valeur du DAG sera remplacé à l'éxécution pour la valeur "scheme" de mon EdS S3 suivi de "://" suivi de la valeur "uri" de mon EdS S3
- si ma chaine déduite commence par "http://" je supprime cette valeur Jje garde donc uniquement la valeur "uri" de mon EdS S3
- si ma chaine déduite comme par "://" (cas où ma propriété "scheme" serait absence de mon EdS S3) alors je ne garde que la valeur "uri" de mon EdS S3
- dans le cas d'autre valeur de scheme (https:// s3:// aws:// ...) alors j'aurais une URL complète avec un protocole définit
Ignorer les propriétés par défaut
La configuration de datapipeline-ui ajoute par défaut un ensemble de propriétés dans la partie configuration avancée de votre DAG pour les briques du mode basique, il s'agit de propriétés obligatoires pour un fonctionnement correcte de la plupart des briques.
Par défaut :
- meta.labels (pour la collecte des logs)
- meta.container.cpuRequest (contrôle des ressources physique)
- meta.container.cpuLimit (contrôle des ressources physique)
- meta.container.memoryRequest (contrôle des ressources physique)
- meta.container.memoryLimit(contrôle des ressources physique)
- image
- imagePullPolicy
Cette liste d'éléments par défaut est configurable (voir dtu-admin)
Vous pouvez empêcher, pour gérer certains cas très spécifiques l'ajout de ces propriété en précisant dans votre YAML d'IHM la propriété
noDefaultProperties: true
Si une valeur par défaut est définie dans les propriétés par défaut datapipeline-ui, mais également dans votre YAML d'IHM, votre configuration surcharge celle des propriétés par défaut.
Ajouter une annotation de dépréciation
Vous pouvez ajouter une information de dépréciation sur une de vos briques en ajoutant à la racine de votre YAML d'IHM la propriété:
isDeprecated: true
Cette propriété est visible en haut du panneau de droite quand on clique sur une brique dans l'éditeur de traitement
Utilisation de secrets kubernetes
Il est possible de monter des secrets présents dans kubernetes en tant que variables d'environnements sur vos pods.
Pour faire cela :
- le secret doit être présennt dans le même namespace que le traitement
- le dag de votre boîte doit contenir une clé meta.container.envFrom contenant :
envFrom:
- secretRef:
name: testme
Pour ajouter cet élément vous pouvez utilisez un widget codeparsed
meta.container.envFrom:
name: envFrom
type: codeparsed
default_value:
- secretRef:
name: testme
Avec cette déclaration, toutes les clés du secret "testme" seront monté dans votre pod en tant que variable d'environnement.
En python vous pourrez par exemple y accéder avec
print(os.environ['MA_CLE'])
Surcharge de propriétés DAG globales en Basic Runtime
Le traitement global, tel qu'il est transmis au moteur en mode basic met actuellement deux propriétés par défaut que vous pouvez choisir de surcharger dans chaque boîte plutôt que de voir s'appliquer le paramètre du traitement global:
messageStore
Autorise le moteur a transmettre les événements trop lourd entre les briques (par défaut supérieur à 1Mo) dans S3 au lieu de terminer en erreur en tentant de passer par Nats.
Cette option est activable ou désactivable au niveau du traitement global dans les paramètres du traitement
Pour contrôler son activation ou pas depuis votre boîte en particulier vous pouvez adapter le code suivant dans votre YAML d'IHM :
globalConfig.messageStore.enabled: # vous devez garder la valeur de cette ligne
name: Message Store
type: boolean
help: Utiliser S3 pour les messages volumineux
default_value: true
autodownload
Permet de recevoir le blob de données du document, et pas uniquement ses métadonnées. Il est renseigné à "false" par défaut au niveau du traitement global sans possibilité de le changer depuis d'IHM
Pour le surcharger dans votre boîte vous pouvez adapter le code suivant dans votre YAML d'IHM :
meta.ki.cible:
name: Répertoire S3
type: edsChoice
type_param: s3
help: Sélectionner le même espace de stockage que celui de la source
required: true
condition:
keyName: 'globalConfig.store.autoDownload'
values:
- true
globalConfig.store.addr: # vous devez garder la valeur de cette ligne
name: Adresse autoDownload S3
type: string
required: true
hidden: true
default_value: '{{ printf `%s://%s` .settings.meta.ki.cible.scheme .settings.meta.ki.cible.uri | trimPrefix `http://` | trimPrefix `://` }}'
condition:
keyName: 'globalConfig.store.autoDownload'
values:
- true
globalConfig.store.user: # vous devez garder la valeur de cette ligne
name: User globalconfig S3
type: string
required: true
default_value: '{{ .settings.meta.ki.cible.username }}'
hidden: true
condition:
keyName: 'globalConfig.store.autoDownload'
values:
- true
globalConfig.store.password: # vous devez garder la valeur de cette ligne
name: Password globalconfig S3
type: password
hidden: true
default_value: '{{ .settings.meta.ki.cible.password }}'
required: true
condition:
keyName: 'globalConfig.store.autoDownload'
values:
- true
globalConfig.store.autoDownload: # vous devez garder la valeur de cette ligne
name: Activation du autoDownload
type: boolean
default_value: true
Tester sa brique
On ne peux pas tester sa brique directement. Il faut tester uniterement son code "métier". Puis faire le test complet dans l'IHM datapipeline. Il n'y a pas d'autre moyen pour tester sa brique.
Appel des API de datapipeline-ui
Cette documentation donne des exemple d'appels curl pour créer des éléments dans datapipeline-ui sans passer par l'IHM.
Créer une session basic-auth
Récupérer une session basic auth en utilisant le user/password dans le secret kube "datapipeline-auth-credentials" en passant par l'ingress :
curl -c cookie.txt -u datapipeline-ui:eDlvR09hZVR6cVZ2YmhLQjNxSFY4N21WYzgxOG9PMnE= https://(datapipeline-uri)/api/login -k
Tester l'appel d'une API simple
curl -b cookie.txt https://(datapipeline-uri)/api/config -k
Swagger: https://(datapipeline-uri)/swagger/index.html
Nous vous conseillons également d'ouvrir un onglet réseau dans l'interface de datapipeline-ui et de manipuler l'IHM pour avoir des exemples de transactions fonctionnelles.
Exemple de création d'un traitements
curl -X POST https://(datapipeline-uri)/api/login \
-H "Content-Type: application/json" \
-b cookie.txt -k \
-d '{"id":"adde71d47-3dca-4e0c-961e-2a6473be4c9a","version":"latest","versionNamed":true,"creationDate":"2025-05-22T08:30:50.20459857Z","modificationDate":"2025-05-22T08:30:50.204598688Z","name":"test","description":"","parallelism":1,"graph":"","environnement":"BAS","runtimeVersion":"1.3.12","memoryRequest":"512Mi","cpuRequest":"200m","cpuLimit":"2000m","memoryLimit":"2048Mi","runtimeMode":"basic","forcedflowname":"","listeZip":"","modeBatch":false,"lastFlowStop":false,"retentionTimeNats":"","messageStore":true,"flux":"","metadatas":{"organisation":["1","2","3","4","5"]}}'
Basic : Modification des propriétés par défaut des briques
Cette procédure permet de personnaliser une liste de propriété par défaut proposées dans l'IHM sur toutes les briques du mode Basique du Data Pipeline.
Par défaut, une liste d'élément est déjà proposée :
- key: meta.labels # paramètre Artemis permettant la différenciation technique/métier pour la collecte des logs
name: labels
type: map
value:
security_zone: '{{ .Securityzone }}'
- help: Quantité minimale de CPU allouée.
key: meta.container.cpuRequest
name: Requête taille CPU
type: string
value: 250m
- help: Quantité maximale de CPU qu'un conteneur peut utiliser.
key: meta.container.cpuLimit
name: CPU max
type: string
value: 500m
- help: Quantité minimale de mémoire allouée au conteneur.
key: meta.container.memoryRequest
name: Requête taille Mémoire
type: string
value: 256Mi
- help: Quantité maximale de mémoire qu'un conteneur peut utiliser.
key: meta.container.memoryLimit
name: Mémoire max
type: string
value: 512Mi
- help: Choix d'une image à partir du registre d'images.
key: image
name: Image
type: string
value: ""
- help: Configuration pour déterminer quand Kubernetes doit télécharger l'image.
key: imagePullPolicy
name: ImagePullPolicy
type: choice[IfNotPresent;Always;Never]
value: Always
Dans l'IHM :
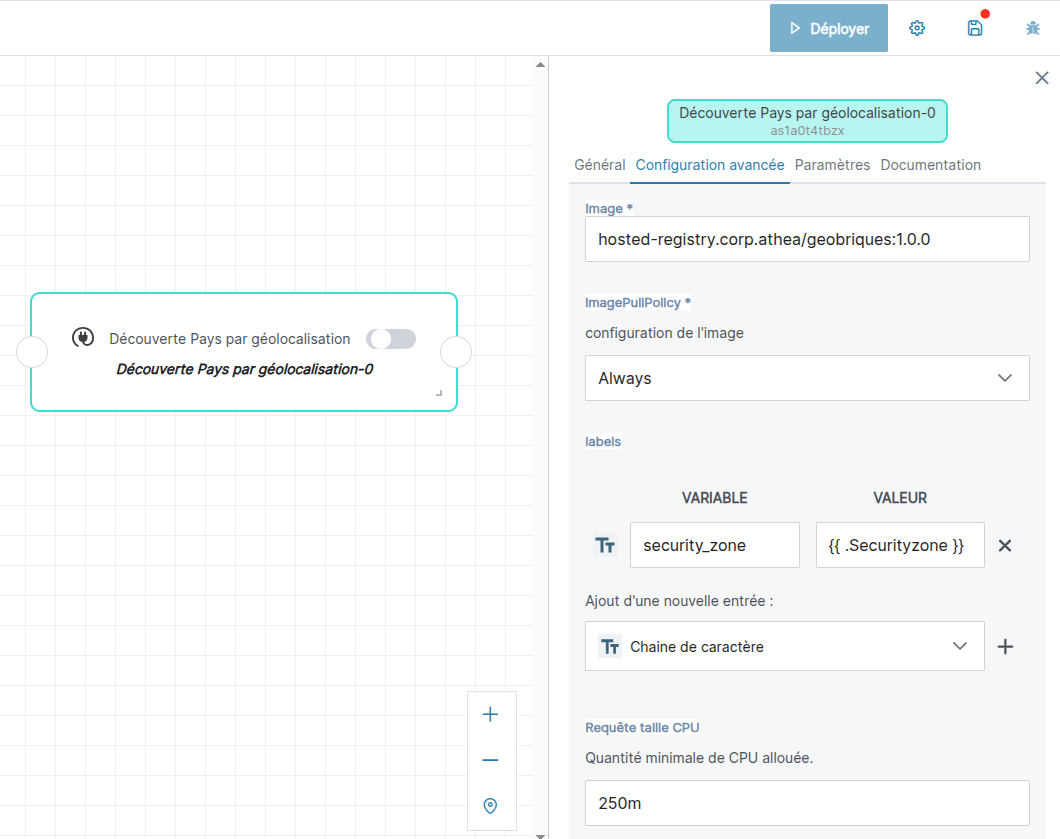
L'ensemble des variables définie sont visualisables dans l'onglet "Configuration avancée" de la brique. Si certaines briques font exception une propriété "noDefaultProperties" peut-être ajoutés par les développeurs de ces briques (voir le manuel de développement, section ajout au catalogue)
Si un développeur précise dans son YAML d'IHM un élément qui est le même qu'une propriété par défaut, la configuration dans la brique prend le dessus (par exemple si la valeur par défaut définie dans cette procédure pour imagePullPolicy est "Always" et que le YAML d'IHM définit "IfNotPresent") c'est "IfNotPresent" qui apparaitra par défaut dans l'IHM quand la brique est ajoutée sur un flux.
L'utilisateur a ensuite la main pour changer les propriétés par défaut lorsqu'il prépare son traitement, il peut ainsi changer imagePullPolicy à "Never" manuellement si il sélectionne cette option dans la configuration avancée de la brique.
Modifier le configmap
Se mettre en modification sur le configmap de datapipeline-ui
# sur plateforme Artemis
kubectl edit configmap -n kosmos-data datapipeline-ui
Modifier la propriété spec.runtime.mode(name=basic).properties
Chaque élément de ce tableau est une propriété différente (donc un input dans l'IHM). Un élément a comme clé possible :
- key (mandatory): définit l'emplacement dans le DAG de la brique ;
- type (mandatory): contient les type tels que définit dans le manuel du développeur dans la procédure
ajout catalogue, celà permet de contrôler l'input proposé ; - value (optionnel): contient la valeur par défaut, celle ci peut-être un string ou un élément plus complexe ;
- help (optionnel): définit les informations pour remplir ce champs (attention à ne pas faire de description trop longue > 144 caractères).
Redémarrer le pod de datapipeline-ui pour prendre en compte la modification :
kubectl rollout restart deploy -n kosmos-data datapipeline-ui
Vérifier le bonne prise en compte
Dans l'IHM du Data Pipeline :
- créer un traitement basic ;
- tirer une brique n'ayant pas "noDefaultProperties" (dans les briques livrée par défaut, seule "S3 EDS", "JSON Brut" et "S3 EDS V2" ont cette propriété) ;
- aller dans l'onglet "Configuration avancée" ;
- vérifier la présence de votre champs.