User Guides
Créer un traitement
Etapes
- Se placer sur la page des traitements (explication : Consulter les traitements).
- Une fois que la page des traitements est affichée, sur le bandeau en haut de la page, cliquez sur le bouton
Créer un traitement(bouton encadré en rouge dans l’image ci-dessous).

Après avoir cliqué, une fenêtre latérale s’ouvre.
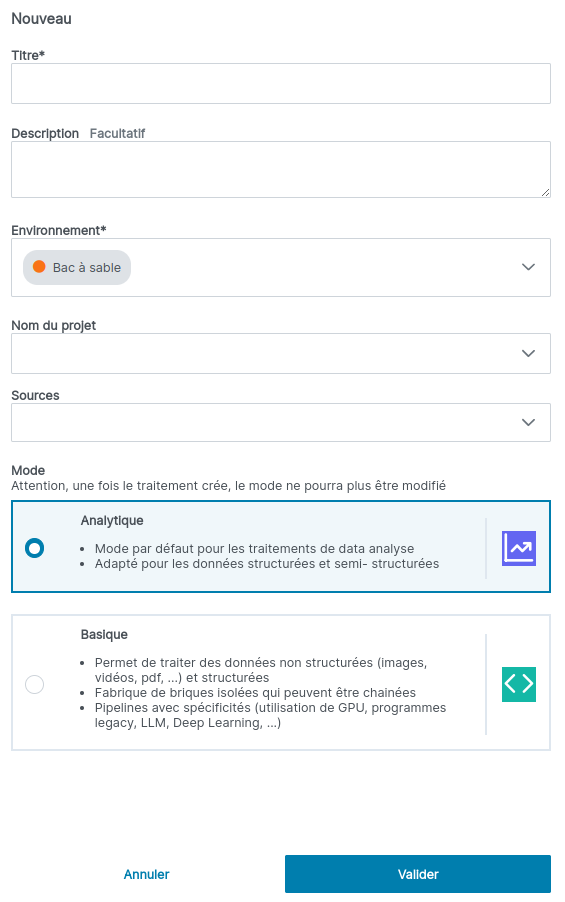
Il faut obligatoirement saisir le titre, la description est facultative, l’environnement est pré-sélectionné sur la valeur “Bac à Sable”, vient ensuite la partie concernant les labels (certains peuvent être obligatoires), enfin il y a le choix du mode (pré-sélectionné sur “Analytique”). Précision : Le titre est unique, si ce n’est pas le cas, le formulaire vous le signalera et il faudra essayer de saisir un nouveau titre. Une fois saisis, cliquez sur Valider.
L'environnement peut être modifié : dans ce cas, si l'utilisateur (data ingenieur) n'accède qu'au Bac à Sable et qu'il modifie l'environnement en "EID" (pour 'transmettre' le traitement en validation), alors il n'aura plus accès au traitement. Il est recommandé, pour éviter cette conséquence, d'exporter le traitement pour le transmettre à l'intégrateur qui pourra alors l'importer dans l'EID.
Consulter les traitements
Cette procédure explique comment consulter les Traitements.
Rôles
- DataX
- Developpeur
- Integrateur
- Superviseur de traitement
Page des Traitements
Sur le bandeau de gauche, il faut cliquer sur la troisième icône en partant du haut (quand on passe la souris sur l’icône, une info-bulle indique “Traitements”).
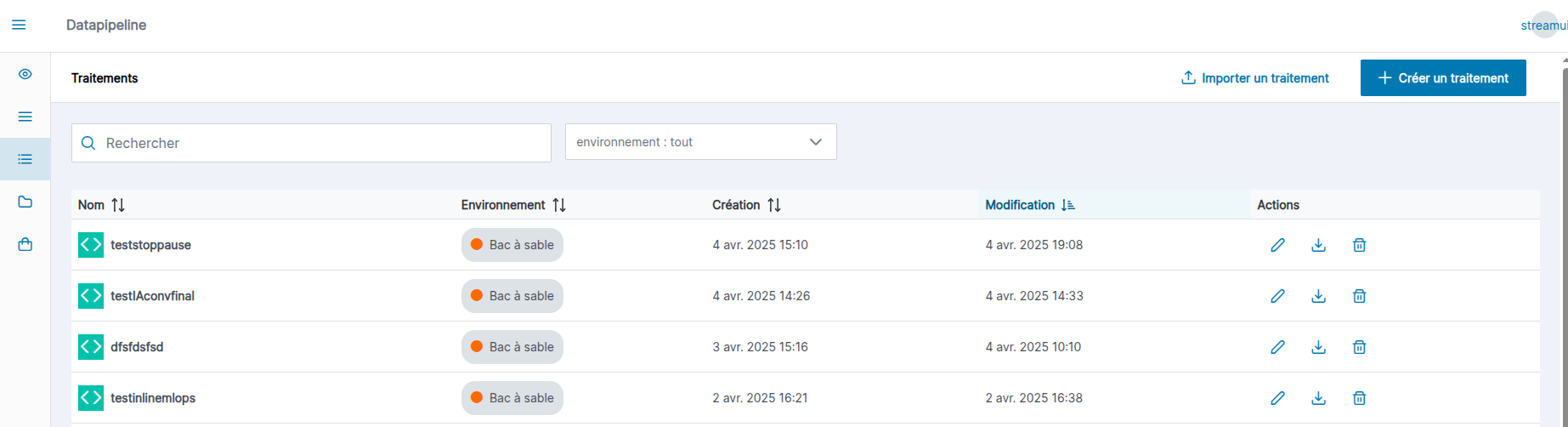
La page des traitements s’affiche sous la forme d’un tableau, dans lequel chaque ligne représente un traitement. Le tableau est composé de plusieurs colonnes :
- La colonne “Nom” :
- avec l'icône du mode choisi (Analytique ou Basique), en passant la souris sur l’icone du mode, le nom de celui-ci apparaît
- ainsi que du nom du traitement et éventuellement la description si elle a été renseignée
- La colonne “Environnement”, contenant l’environnement où peut être déployé le traitement
- La colonne “Création”, contenant la date de création du traitement
- La colonne “Modification”, contenant la date de dernière modification du traitement
- La colonne “Action”, qui permet d’éditer, d'exporter, ou de supprimer un traitement
Page des traitements :
Ordonner la liste des traitements
Cliquer sur les flèches situées à droite du titre des colonnes.
Plusieurs tris sont possibles, mais un seul est possible à la fois.
- par ordre alphabétique ou ordre alphabétique inversé sur les colonnes “Nom” ou “Environnement”.
- par ordre chronologique ou antéchronologique sur la colonne “Création” ou “Modification”.
Filtrer la liste des traitements
Il est possible de filtrer les traitements soit par leur nom soit par leur environnement :
- Filtrer par nom : Se placer sur le champ “Rechercher” et écrire le nom du traitement recherché.
- Filtrer par environnement : Se placer sur le champ “environnement” et sélectionner les environnements (0 ou plusieurs) recherchés grâce à la liste déroulante.
Editeur de traitement
Pour ouvrir un traitement et accéder à l'éditeur, deux options sont possibles :
- Colonne "Nom" : cliquer sur le nom du traitement
- Colonne "Actions" : cliquer sur la première icône Ouvrir
Construire un traitement
Cette procédure explique comment construire un traitement. Les deux étapes de construction d’un traitement sont :
- Le drag and drop et la liaison des briques ;
- La complétion des paramètres des briques.
L'utilisateur peut consulter les traitements pour sélectionner celui qu'il veut modifier ou bien en créer un nouveau. Il paramètre et teste ce traitement jusqu'à obtenir des données de qualité suffisante.
Pour cela, il déploie le traitement, observe les premiers résultats et stoppe le traitement si le jeu de test est trop important ou les résultats non satisfaisants.
Il le sauvegarde, il peut l'exporter pour ensuite le transmettre :
- à l'intégrateur en charge de le tester dans l'EID ;
- au superviseur de traitement en charge de le déployer en production. [Mise en production d'un traitement](../../../User Guidelines/legacy_deploy_flow)
Si le traitement est devenu obsolète, alors il peut le supprimer.
Rôles
- DataX
- Developpeur
- Superviseur de traitement
Présentation de l'interface
Se rendre sur la page d’édition d’un traitement (explications disponibles dans la procédure “Consulter les traitements - Etape 1 et Etape 3” ici). Le panneau de droite affiche par défaut la configuration du traitement. Si ce panneau est fermé il peut être ré-ouvert en cliquant sur l'icône "rouage".
Description des briques
- S3 EdS (une version S3 EdS V2 est disponible)
Briques sources
Les briques sources servent à lire des données, elles sont composées uniquement d’une sortie (on tire le trait de liaison toujours en partant de la source).
Les briques sources sont toujours entourées d’une bande bleue.
Exemple d’une brique source :

Elles ne peuvent être liées qu’à des fonctions ou des cibles.
Briques fonctions
Les briques fonctions servent à modifier/transformer des données, elles sont composées d’une entrée et d’une sortie. Les briques fonctions sont toujours entourées d’une bande verte.
Exemple d’une brique fonction :

- En entrée, elles peuvent être liées à des briques du même type ou de type source. (réception d’un trait de liaison ou plusieurs)
- En sortie, elles peuvent être liées à des briques du même type ou de type cible. (on tire le trait de liaison toujours en partant de la sortie)
Briques cibles
Les briques cibles servent à recevoir des données. Ce type de brique est composé exclusivement d’un port d'entrée. Les briques cibles sont toujours entourées d’une bande rose.
Exemple d’une brique cible :

Elles peuvent être liées qu’à des fonctions ou des sources. (réception d’un trait de liaison)
Panneau de briques
Une fois que la page d’édition d’un traitement est ouverte, on constate la présence sur la gauche d’un panneau mobile. Ce panneau peut être réduit si besoin en utilisant la flèche droite pointant vers la gauche ou bien déplacer en cliquant et maintenant appuyé la sourissur la barre grise en haut du panneau.
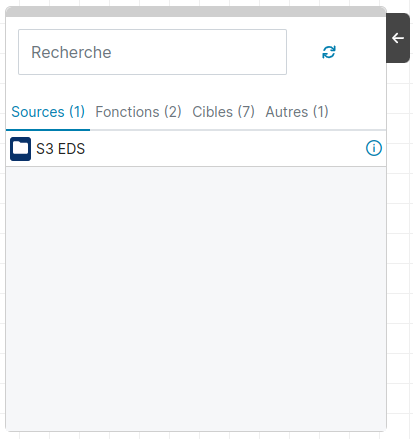
Ce panneau est composé de 4 sections : “Sources”, “Fonctions”, “Cibles”, "Autres". Pour afficher une section, il suffit de cliquer sur son titre (“Sources”,“Fonctions” ou “Cibles”). L'onglet sélectionné devient bleu souligné et la liste de brique s’affiche.
Un champ “Recherche” est aussi à disposition pour filtrer les résultats. Il s'appuie sur le nom de la brique, en fonction de l’inclusion de la valeur saisie dans les noms des briques affichées (uniquement celles de la section sélectionnée).
Si un brique vient d'être ajouté ou retiré, il est possible que la liste de briques ne soit pas à jour. Pour mettre à jour la liste, cliquer sur le symbole rafraîchissement à droite du champ “Recherche”. En cas d’erreur, une pop-up s’affiche en haut à gauche de l’écran, signalant que la synchronisation a échoué.
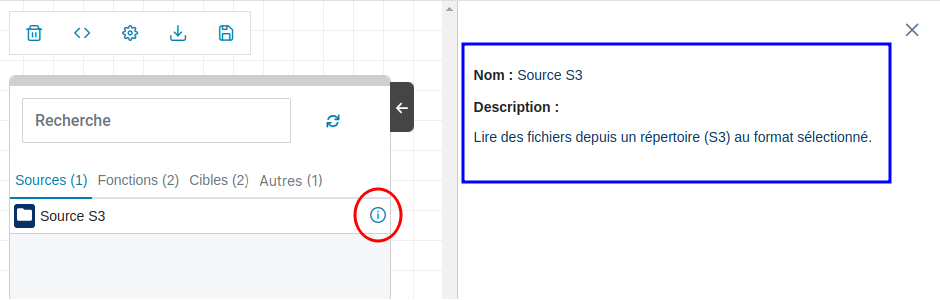
Documentation d’une brique
Une documentation est disponible directement accessible via l'IHM (assurez-vous que le panneau de brique ne soit pas réduit). Elle est consultable en cliquant sur l'icône information de la brique. l’icône information.
Drag & Drop
Se placer sur le panneau d’édition de brique, positionner la souris sur la ligne de la brique souhaitée, maintenir le clic et faire glisser la brique au niveau de la zone d’édition d’un traitement (toute la zone quadrillée, affichée à l’écran), quand la brique se trouve au-dessus de la zone désirée, lâchez le clic.
Lier les différentes briques entre elles
Suivre les règles listées dans la description des briques
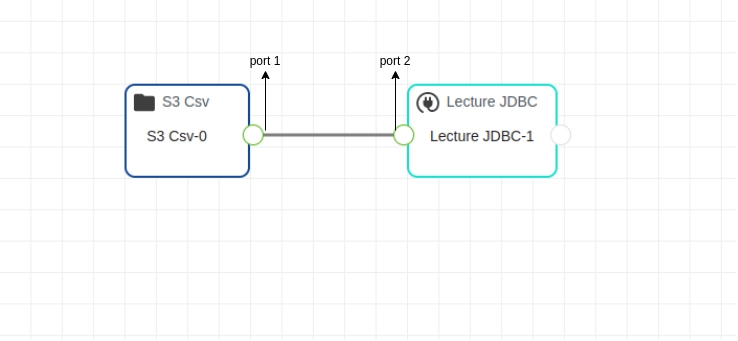
Cliquez sur le port de sortie de la brique de départ, maintenir le clic vers le port d'entrée de la brique d'arrivée, quand celui-ci est atteint lâcher le clic. Un trait continu va se matérialiser de la brique avec le port de sortie (port 1) vers la brique avec le port d'entrée (port 2).
Dupliquer une brique
Sélectionner une brique, cliquer sur les touches Ctrl+C, une pop-up s’ouvre avec le message suivant : “Voulez-vous dupliquer ce composant ?”. Cliquer sur “ok” pour confirmer.
Redimensionner une brique
Se positionner sur la brique que vous souhaitez redimensionner, dans le bord inférieur gauche, une zone permet le rédimensionnement de la brique (entourée en rouge sur l'image ci-dessous).

Cliquez et bougez la souris dans la direction que vous désirez selon que vous souhaitez augmenter/diminuer la largeur/hauteur de la brique.
Ajouter un commentaire
Se rendre dans l'onglet Autres du panneau qui contient une entrée Commentaire permettant d'ajouter une note sur l'éditeur du traitement. Le principe est le même que pour l'ajout de briques, il faut drag & drop l'objet sur le graphique à la position que l'on souhaite.
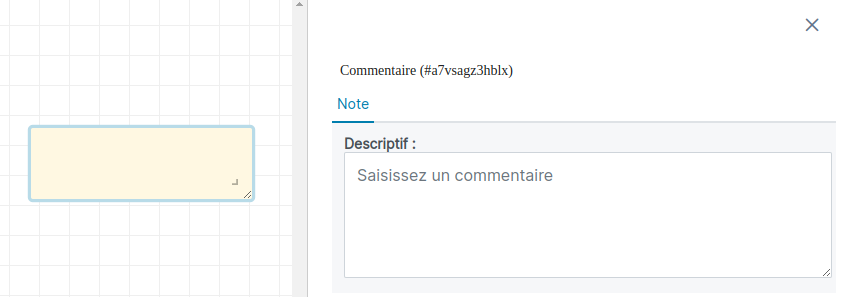
Un nouveau rectangle jaune est alors ajouté au graphique et une zone de saisie est est affichée dans la sidebar latérale. Tout texte ajouté se retrouvera sous forme de note sur la zone d'adition après la sauvegarde des modificatiosn apportées.
Zoomer, Dézoomer, Recentrer, Reordonner
Vous avez la possibilité d'ajuster la vue de votre éditeur de traitement, en zoomant, dézoomant, recentrant et réordonnant votre graphique.

- La première icône "+", permet de zoomer sur le graphique
- La seconde icône "-", permet de dézoomer sur le graphique
- La troisième icône "Recentrer", permet de recentrer l'éditeur sur l'ensemble du traitement.
- La dernière icône "Ordonner", change la position de vos briques pour les mettre sur une grille
Compléter les paramètres des briques
Se placer sur une brique présente dans l'éditeur graphique, double-cliquer dessus.
Sur le panneau de droite les paramètres de la brique s’affichent, les champs requis sont indiqués avec le caractère ’*’.
Au minimum dans les paramètres d’une brique, il y a deux sections :
- Paramètres où l’on peut changer le nom de la brique ;
Dans le cadre d’un flux versionné dit “de production”, les champs qui contiennent des users ou password de moyens de stockages sont automatiquement remplacés lors du déploiement de la version avec SAP
- La documentation qui décrit les spécificités de la brique.
Il peut y avoir plus de sections, il faut toutes les parcourir et saisir les champs obligatoires (l’astérisque est l’indicateur des champs obligatoires)
Suppression d’éléments graphiques
Suppression d’une brique
Se placer sur une brique présente dans l'éditeur graphique, cliquer dessus. Suite au clic, la brique sélectionnée change de couleur. Cliquez sur le bouton “suppr” de votre ordinateur. Une pop-pup s’ouvre, cliquez sur “ok”.
Suppression d’un lien
Cliquez sur un lien, le lien sélectionné change d’état comme on le voit dans l’image ci-dessous
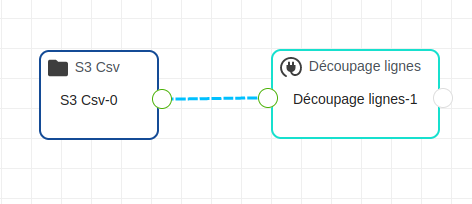
Il existe 2 possibilités pour supprimer un lien :
- Cliquez sur le bouton “suppr” de votre ordinateur. Une pop-pup s’ouvre, cliquer sur “ok”.
- Effectuez un clic droit en se plaçant sur le lien.
Suppression de l’entièreté du graphique
Cliquez sur l’icône poubelle de la barre des tâches (encadré en rouge sur l’image ci-dessous)
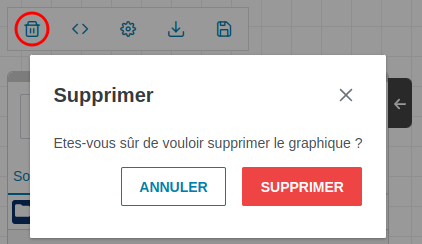
Une pop-pup s’ouvre, cliquez sur “Supprimer”.
Dag - Description technique
Cette description est utilisé à des fins de debug dans les phases de développement et pour échange avec le support si nécessaire.
La vue DAG (Directed Acyclic Graph) est la représentation json du traitement construit. Il permet à un utilisateur d'avoir une vision technique de son traitement. Il est accessible en cliquant sur l’icône Debug de la barre de tâche (encadré en bleu sur l’image ci-dessous).
Une vue kflow est aussi disponible. C'est la représentation json du traitement avec tout ses paramètres auxiliaires transmis au moteur, les mots de passes en moins, vous pouvez passer de l'un à l'autre avec le menu en haut (rectangle rouge sur l'image).
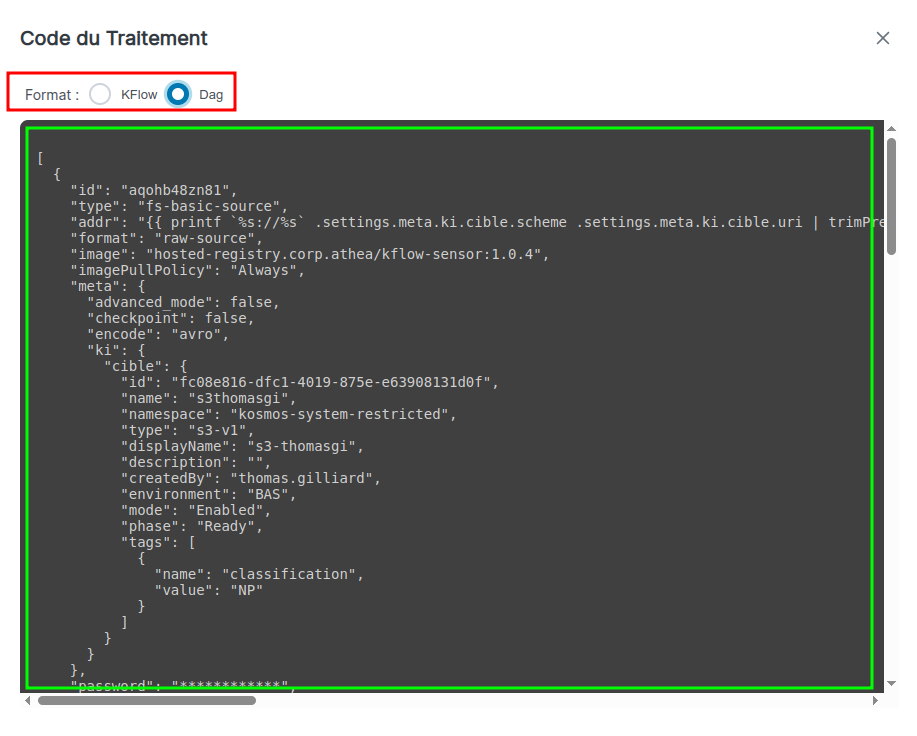
Pour rafraîchir le dag ou la transaction kflow fermez la pop-up, puis recliquez sur l’icône Debug.
Principes généraux
Choix des EdS
Les briques Sources et Cibles qui correspondent à des EdS permettent de choisir l'espace de stockage parmi ceux existants et disponibles pour l'utilisateur.
LesEdS disponibles (autorisés) pour l'utilisateur connecté sont ceux qui respectent les règles de la politique ABAC sur les EdS. Pour plus d'information, voir le [process sur les EdS](../../User Guidelines/Mettre-en-service-des-EdS.md).
Sur les EdS en mode basique, il est également possible d'activer le mode checkpoint dans la section "mode avancé". Ainsi, pendant un lancement avancé, cela permet de conserver la progression des traitements si l'on effectue un arrêt puis une reprise du traitement.
Schémas Avro
En mode basique, la solution s’appuie sur des schémas avros, notamment pour décrire le format de certaines entrées ou sorties.
Par exemple, la brique s3 qui fournit les fichiers d'un bucket, présente le schéma suivant :
{
"type": "record",
"name": "s3list",
"namespace": "tech.athea.kosmos",
"fields" : [
{
"name": "url",
"type": "string"
},
{
"name": "lastModifiedUnixMilli",
"type": "long"
},
{
"name": "bucket",
"type": "string"
},
{
"name": "key",
"type": "string"
}
]
}
Ce schéma indique au moteur qu’il doit sérialiser un objet de type record qui contiendra 4 colonnes, dont les noms seront (dans l’ordre) : url, lastModifiedUnixMilli, bucket et key.
Plus loin dans le traitement, vous pourrez référencer ces noms de colonnes lors de diverses opérations.
Inférence des données
Il est possible d'ajouter des inférences de schéma dans les éléments du DAG. C'est à dire utiliser des valeurs de données comme valeurs dynamiques.
Il faut que des schémas soient définis dans les briques du traitement au format avro et qu'ils présentent des variables de contexte (élément dont la valeur réelle est inconnue de l'utilisateur au moment où il la place, mais qui est remplacée au lancement). Si la brique sélectionnée a, sur certains de ses champs, la propriété "inference" activé dans le YAML (inference: true - voir dtu-developpement), alors l'utilisateur aura le choix de basculer en mode inférence via une checkbox (entourée en vert, sur l'image ci-dessous).
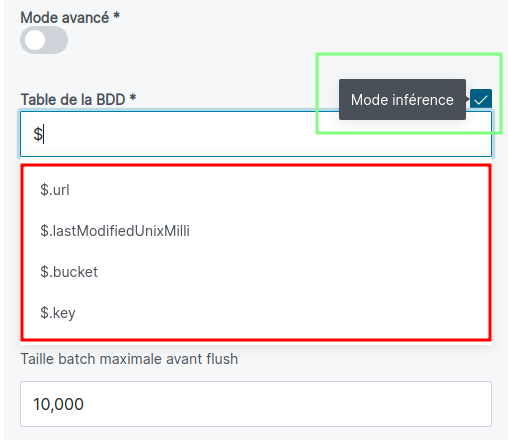
S'il active cette case, alors un champ de saisi autocomplété se présentera à lui pour lui permettra d'avoir accès aux différentes variables (entourées en rouge sur l'image ci-dessus) définies dans les schémas des briques précédentes et de sélectionner la valeur qu'il souhaite par autocomplétion.
Exporter un traitement
Cette procédure explique comment exporter un traitement. L'export d'un traitement exporte uniquement son enchainement de briques et leurs paramètres. L'export n'exporte pas les briques utilisées par le traitement.
Procédure
Dans l’application il y a deux façons pour exporter un traitement :
- Soit sur la page qui liste les traitements (explication [ici]). Une fois que la page des traitements est affichée, sur la ligne du traitement que vous souhaitez exporter, dans la colonne “Action”, cliquez sur la flèche pour exporter le traitement.
- Soit depuis l'éditeur du traitement, sur la barre d’outils à droite du titre, cliquez sur la quatrième icône en partant de la gauche (le symbole flèche vers le bas, qui est entouré en rouge dans l’image ci-dessous).

Un fichier “nom_du_traitement”.json est exporté.
Superviser les flux
Sur le bandeau de gauche, il faut cliquer sur la première icône en partant du haut (quand on passe la souris sur l’icône, une info-bulle apparait indiquant “Supervision”).
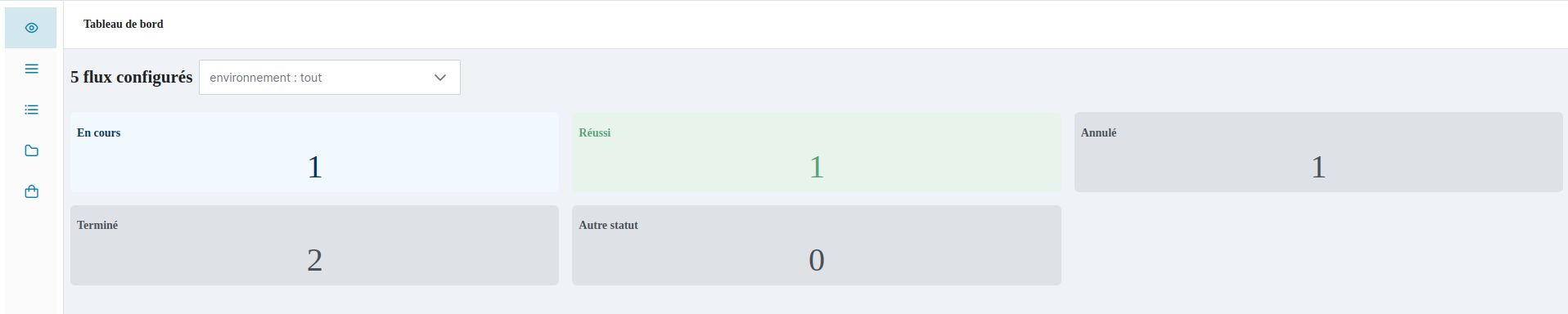
La page de Supervision apparait et affiche :
- Le nombre total des flux exécutés (texte au-dessus des encarts)
- La possibilité de sélectionner les flux exécutés par environnement (0 ou plusieurs) grâce à la liste déroulante à droite du nombre total des flux exécutés.
- Le nombre de flux en cours d’exécution (encart “En cours”) qui s’affiche en vert si la valeur est supérieure à 0
- Le nombre de flux qui se sont terminés avec succès (encart “Réussi”) qui s’affiche en vert si la valeur est supérieure à 0
- Le nombre de flux annulés (encart “Annulé”).
- Le nombre de flux terminés (encart “Terminé”).
- Le nombre de flux avec un statut inconnu (encart “Autre statut”) qui s’affiche en gris
Un encart qui a pour valeur 0, aura un fond gris
Quand on survole un encart, celui-ci est alors encadré en gras et un lien “Voir flux” apparait (exemple avec l’encart en cours dans l’image ci-dessous).

Lorsque vous cliquez sur Voir flux vous êtes redirigé vers la page des flux. Sur cette page, vous verrez uniquement les flux avec le statut de l’encart survolé et avec les environnements sélectionnés dans la page de supervision.
Présentation de la page des flux ici.
Consulter les flux
Un flux est un traitement qui est lancé. Cette procédure explique comment consulter les flux.
Se rendre sur la page des flux
Sur le bandeau de gauche, il faut cliquer sur la deuxième icône en partant du haut (quand on passe la souris sur l’icône, une info-bulle apparait indiquant “Flux”).
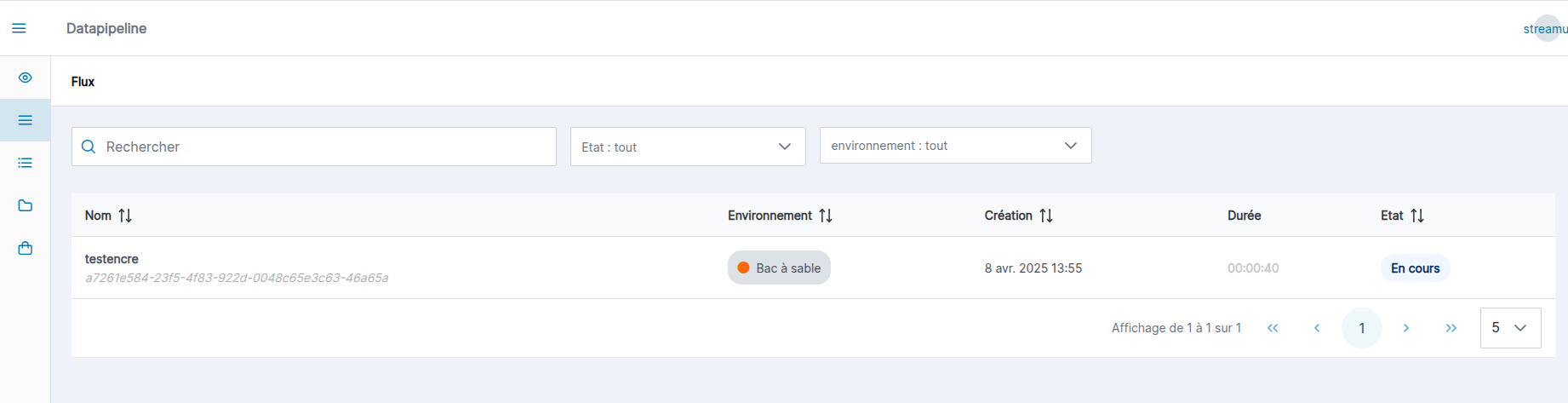
La page des flux s’affiche sous la forme d’un tableau, dans lequel chaque ligne représente un flux. Le tableau est composé de 6 colonnes :
- La colonne “Nom”, avec l’identifiant du flux et son nom.
- La colonne “Environnement”, avec la valeur de l'environnement dans lequel s'exécutge le flux.
- La colonne “Labels”, avec les différents labels associés au flux
- La colonne “Création”, la date de création du flux.
- La colonne “Durée” : depuis combien de temps le flux s'exécute, où s'il est terminé le temps d'exécution de celui-ci
- La colonne “Etat”, on retrouve le statut qui est coloré en suivant les règles du panneau de supervision ici
Filtrer un flux par nom ou id
Se placer sur le champ “Filtrer sur le nom ou l’id” et écrire le nom ou l’identifiant du flux recherché.
La liste des traitements est filtrée en fonction de l’inclusion de la valeur saisie dans la barre de recherche dans les noms ou identifiants des traitements affichés
Ordonner la liste des flux
Cliquez sur les flèches à droite des colonnes “Nom”, “Environnement”, “Création”, “Etat”, pour les trier selon le critère souhaité.
Plusieurs tris sont possibles :
- ordre alphabétique ou ordre alphabétique inversé, en cliquant sur la flèche de la colonne sur laquelle on souhaite réaliser le filtre.
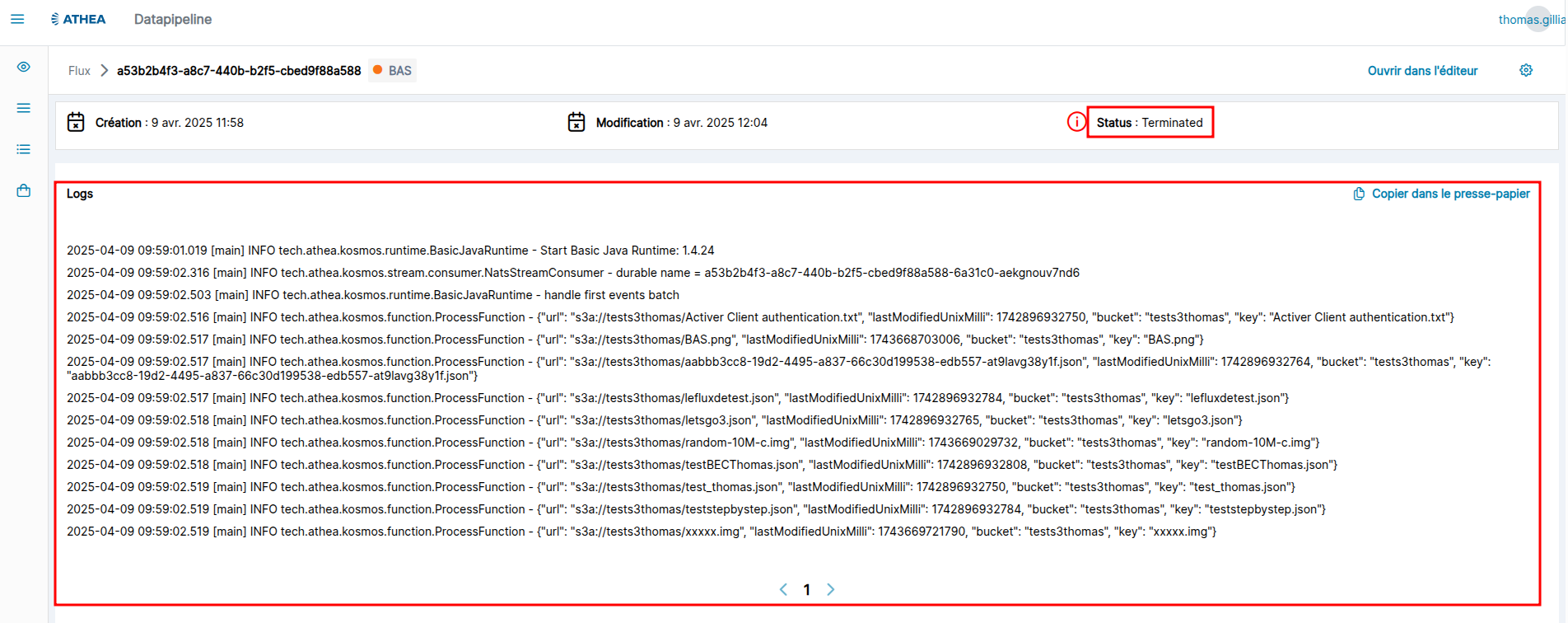
Détails d’un flux
Pour accéder au détail d’un flux, cliquez sur le nom du flux (première colonne). La page du détail d’un flux s’affiche :

Description des zones encadrées dans l’image ci-dessus :
- (rouge) : Identifiant du flux et l'environnement dans lequel il s'exécute
- (violet) : Actions
- Ouvrir dans l'éditeur pour pouvoir l'éditer
- Stopper un flux selon si son état est en cours d'exécution
- Paramètrage en mode avancé
- (Orange) : Date de Création
- (Vert) : Statut du flux
- (Bleu) : Panneau des logs
S'authentifier dans datapipeline
Datapipeline peut être configuré avec ou sans authentification Keycloak et avec ou sans authentification basique.
Si aucune authentification n'est disponible, datapipeline peut-être paramétré pour ne requérir aucune authentification.
Le choix d'authentification
Dans le cas où les authentification Keycloak et basique sont disponible sur votre plateforme, il vous faut choisir le mode voulu au moment de la connexion
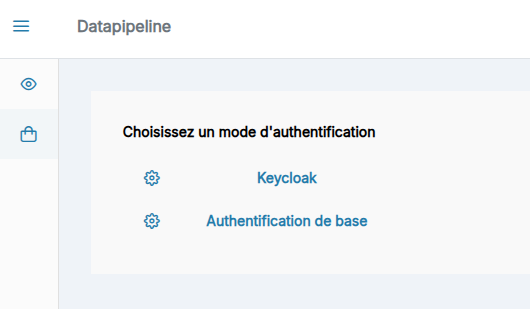
En cas de choix Keycloak vous serez redirigé vers la mire de login de Keycloak
En cas de choix de l'authentification basique vous serez invité à saisir un nom d'utilisateur et un mot de passe. Pour le moment il n'existe qu'un seul user et mot de passe, celui d'administration, la liste des users basique auth n'est pas personnalisable.
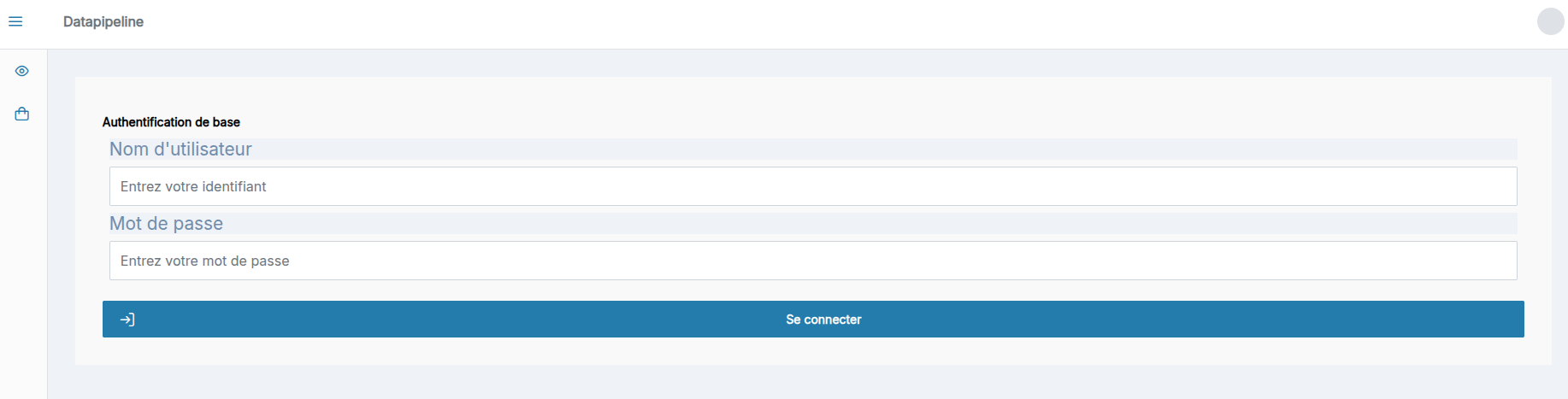
Une seule authentification disponible
Si une seule identification est disponible, vous serez redirigé directement sur la seul mire de login disponible.
Consulter les logs d'un traitement
Les logs ne sont par persistés, ils sont affichés en temps réel. Pour suivre le déroulement d'un traitement, il faut être sur la page du traitement en question.
Visualisation des logs d'un flux en cours
Quand un flux est en cours, on a dans l'éditeur, un panneau en bas de page qui présente l'état du flux ainsi que les logs.
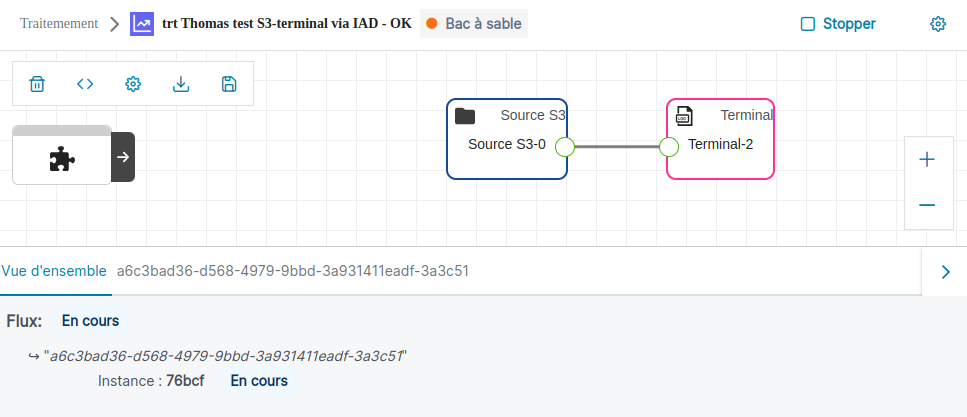
Le panneau est scindé en plusieurs onglets :
- Onglet général "Vue d'ensemble"
- Onglet(s) du/des pod(s).
Vue générale
Sur la vue générale, on retrouve plusieurs informations :
- L'état du courant du flux
- Les différents pods avec leurs instances et statuts
Si c'est le traitement est en mode Analytique, on aura un seul POD sur lequel récupérer les logs. En revanche pour le mode Basique, on aura un POD par brique, et les logs associés. Dans ce mode, cliquer sur une brique vous fera naviguer vers sa fenêtre de log spécifique.
Onglet(s)
L'IHM peut présenter plusieurs onglets en fonction du mode choisi.

Chaque onglet aura la présentation suivante (fois le nombre d'instance du pod) :
- Le nom de l'instance ainsi que son état courant (encadré en bleu dans l'image ci-dessus).
- L'historique des différents états par lequel il est passé (encadré en orange dans l'image ci-dessus).
On peut ensuite accéder aux différents statuts et avoir les logs associés. L'utilisateur peut accéder aux types de logs via la sélection disponible en haut à droite (encadré en rouge dans l'image ci-dessus). Cela correspond aux informations remontées par Kubernetes. Il est possible d'accéder aux logs courants, aux logs précédents ou au motif de l'état : ce qu'on voit dans "Motif" c'est ce qu'on obtient avec un "kubectl describe" sur un pod qui a pas démarré.

En fonction de la sélection, seront affichés les logs ou l'intitulé "Pas de logs disponibles" dans le cas où il n'y pas d'information remontée par le POD pour le statut sélectionné.
Visualisation des logs d'un flux terminé
Une fois un flux terminé, les logs sont archivés et peuvent être rendu sur l'interface du flux. Il ne sont plus disponible sur l'éditeur de traitement qui n'affiche que les logs d'un flux en cours
Pour voir les logs d'un flux terminé, sélectionnez le dans la liste des flux.
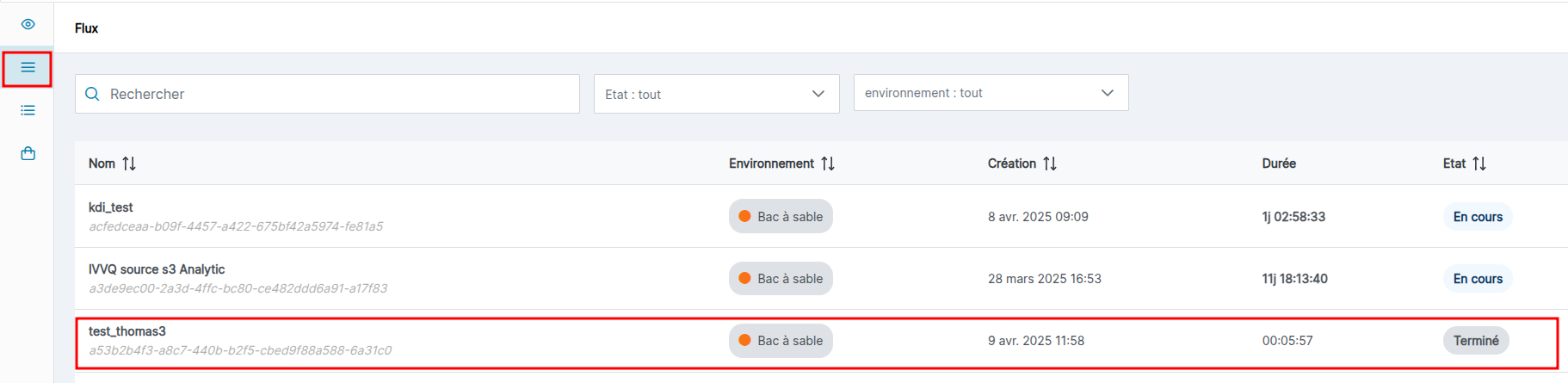
Si des logs sont disponibles, ils apparaitront dans l'interface, il ne faut plus trier par pods mais par timestamp.
Gérer les briques
Cette procédure explique comment gérer le catalogue des briques (ou fonctions) :
- consulter les briques ;
- importer et mettre à jour des briques ;
- supprimer une brique.
Consulter les briques
Sur le bandeau de gauche, il faut cliquer sur la cinquième icône en partant du haut (quand on passe la souris sur l’icône, une info-bulle indique “Catalogue des briques”).
La page du catalogue de briques s’affiche est se présente comme sur l'image ci-dessous :

Différentes zones ont été entourées :
- Rouge : Icône du menu latéral pour accéder à la page du catalogue des briques ;
- Vert : L'en-tête avec le nom de la page ainsi que le bouton à droite pour importer de nouvelles briques ;
- Bleu : Zone permettant de filtrer les données via :
- Une recherche par nom ;
- Sélection via un type de brique (Toutes/Analytique/Basique) ;
- Tri par ordre alphabétique ou inverse ;
- Orange : Affichage du catalogue de briques sous trois onglets (Sources/Fonctions/Cibles) ;
- Les briques sont classées et affichées sous trois onglets en fonction de leur catégorie ;
- Violet : Ligne d'une brique :
- Partie de gauche :
- Icône du type (Analytique ou Basique), nom de la brique, auteur ;
- Au clic : Description de la brique si elle est renseignée ;
- Partie de droite, les différentes actions possibles :
- Icône crayon : Edition de la brique ;
- Icône poubelle : Suppression de la brique.
- Partie de gauche :
Ordonner la liste des briques
Cliquer sur l'icône tout à droite dans la zone encadrée en bleu sur l'image précédente. Les données de l'onglet sélectionné sont triées par ordre alphabétique ou ordre alphabétique inversé d'après le nom de la brique.
Filtrer la liste des briques
Il est possible de filtrer les briques par leur nom et/ou par leur type :
- Filtrer par nom : Se placer sur le champ “Rechercher” et écrire le nom de la brique recherchée ;
- Filtrer par type : Se placer sur la liste déroulante de la zone entourée en bleu sur l'image précédente et choisir le type (Toutes/Analytique/Basique) sur lequel appliquer le filtre.
Importer une nouvelle brique
Pour ajouter une nouvelle brique, cliquez sur le bouton situé à droite de la zone verte "Importer une brique" de la première image.
Cette action va déclencher l'ouverture du panneau latéral de droite avec un formulaire à remplir pour permettre l'ajout d'une brique.
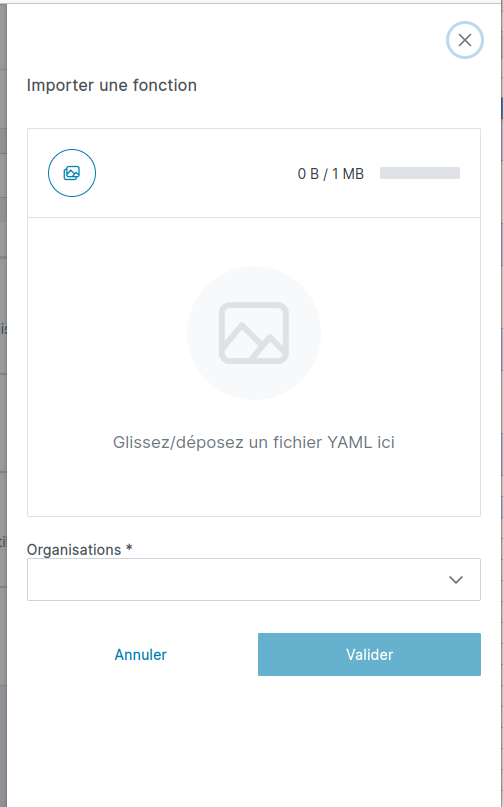
Elle est composée de différentes parties :
- titre "Importer une fonction" ;
- Zone pour ajouter le fichier YAML de la brique à importer ;
- Via un clic sur le bouton pour choisir un fichier, qui ouvre l'explorateur de fichiers de l'ordinateur pour sélectionner celui que l'on souhaite ajouter ;
- Via un "Glisser/Déposer" situé en-dessous.
Une fois le fichier importé, on a un descriptif avec son nom, la date, le poids du fichier et la possibilité de le supprimer via la croix rouge à droite.
- Zone avec les labels s'il y en a, qui peuvent être appliqués à la brique :
- Les labels obligatoires sont suivis d'un astérisque (*) et devront être renseignés pour pouvoir soumettre le formulaire ;
- Exemple le champ "Organisations" de l'image ci-dessus.
- Les labels obligatoires sont suivis d'un astérisque (*) et devront être renseignés pour pouvoir soumettre le formulaire ;
La partie exécutable d'une nouvelle brique est importée via le service applicatif (fonction d'import) en suivant les indications de packaging du guide de développement.
Ajout d’une icone
Les icônes permettent d'identifier visuellement votre brique dans la liste des briques de l'éditeur de traitement.
Pour ajouter un icône il faut le placer dans le dossier definitions/icons du bucket S3 qui est défini comme le bucket de configuration de l’UI (par défaut le bucket datapipeline-icons du S3 Technique). Il faut en faire la demande auprès d'une personne ayant le rôle administrateur système.
La structure du dossier est la suivante :
definitions # racine du dossier
|_ icons # dossier des icônes
Une fois les champs requis saisis, le formulaire peut être soumis via le bouton Valider ou annulé via le bouton Annuler (ou en cliquant sur le bouton avec la croix tout en haut à droite de la page).
- Si l'ajout fonctionne une pop-up de confirmation apparaît. La liste des briques est mise à jour avec ce nouvel ajout et le catalogue des briques présente alors cette nouvelle brique.
- Si l'ajout a présenté une erreur (nom de la brique déjà existant, par exemple), une pop-up explicative sera présentée à l'utilisateur pour donner plus de détails.
Edition d'une brique
Si l'on souhaite modifier une brique existante, cela se fait via le bouton d'édition (icône crayon), présent sur chaque ligne comme celle entourée en violet sur la première image, du tableau des briques. Un clic sur cette icône va permettre l'ouverture d'un panneau latéral. Le principe d'édition et le même que celui de la création, ajouter le YAML modifié de la brique à mettre à jour, remplir les labels obligatoires et soumettre le formulaire :
- Si la mise à jour se passe correctement, une pop-up en avertit l'utilisateur et la liste des briques est mise à jour avec les nouvelles données de la brique modifiée ;
- Dans le cas contraire, une pop-up est affichée pour donner plus de détails à l'utilisateur quuant à l'échec de la mise à jour de la brique.
Suppression d'une brique
Si l'on souhaite supprimer une brique existante, cela se fait via le bouton de suppression (icône poubelle), présent sur chaque ligne comme celle entourée en violet sur la première image, du tableau des briques. Lors du clic sur cette icône, une fenêtre de confirmation apparaît pour demander une confirmation à l'utilisateur :
- S'il valide l'action via le bouton
Supprimer, une pop-up en informe l'utilisateur et la brique est retirée de liste sur la page ; - Si la suppression échoue, l'utilisateur est notifié et la liste des briques reste inchangée.
Gérer les versions d'un traitement
Cette procédure explique comment gérer les versions d'un traitement.
Une version d'un traitement permet de conserver et éventuellement de restaurer un traitement avec toutes ses propriétés. C'est à dire son schéma, le code contenu dans ses briques inlines mais également ses paramètres.
Se rendre sur la zone des versions
La zone des versions s'ouvre dans un menu à droite
Créer une version nommée
Un bouton + est présent dans le menu, cliquez dessus pour créer une version nommée.
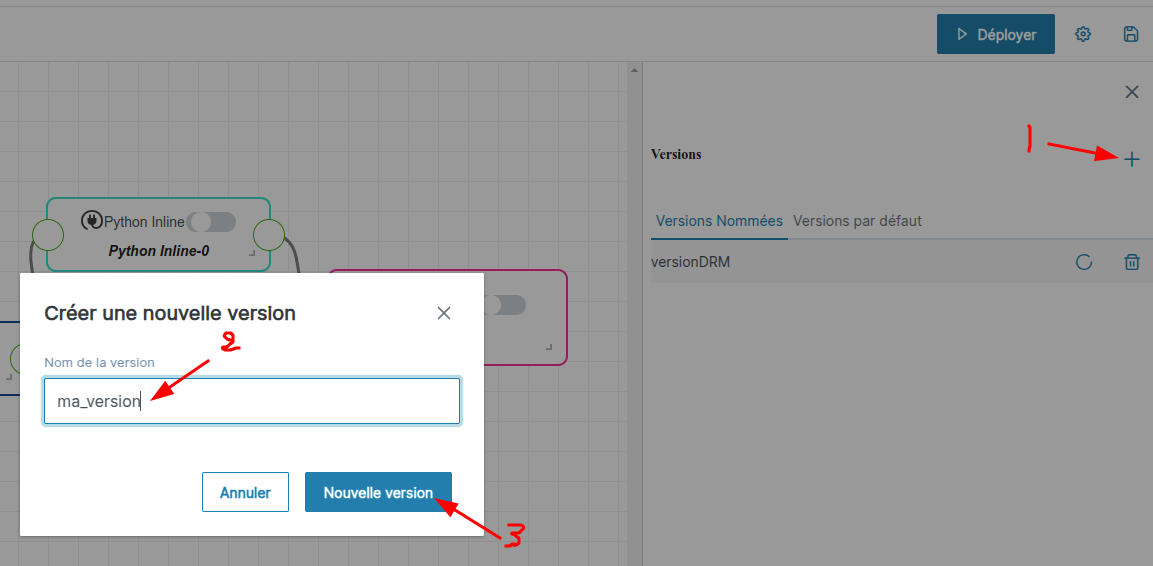
Une nouvelle version utilisant le nom demandé est créée.
Créer une version par défaut
Aucune manipulation spécifique n'est nécessaire, les versions par défaut sont créées à chaque sauvegarde. Une nouvelle version est créée à chaque fois que le bouton sauvegardé est utilisé ou la combinaison Ctrl+S enclenchée.
Parcourir la liste des versions
Un menu avec deux onglets est disponible dans le menu, le premier onglet affiche les versions par défaut si au moins une existe, le second affiche les versions nommées si au moins une existe.
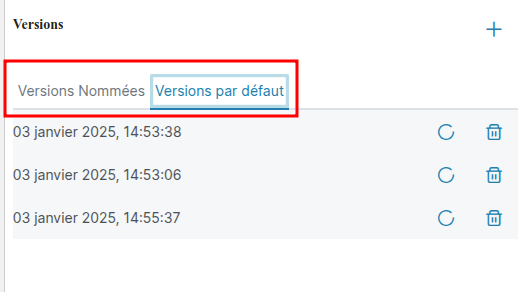
Restaurer une version
Appuyez sur le l'icône rond en face d'une version pour que cette version devienne la version courante. La version courante est la seule qui peut être modifiée et lancée. L'utilisation de ce bouton vous demandera une validation, en effet si des modifications étaient en cours et n'ont pas été sauvegardée dans aucune version elle seront perdues.
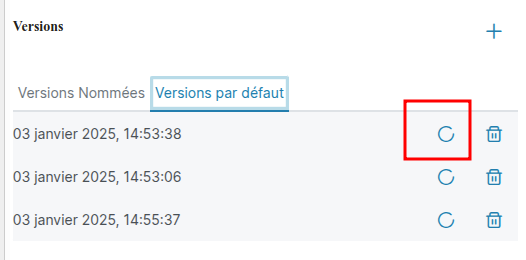
Supprimer une version
Appuyez sur l'icône Poubelle en face d'une version pour supprimer celle-ci, une fois une version supprimée il n'est plus possible de récupérer son contenu.
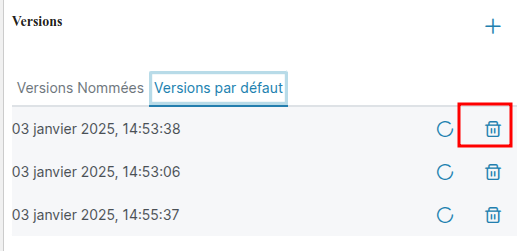
Importer un traitement
Etape 1 - Importer un flux
Sur le bandeau du haut de la page, cliquez sur le bouton Importer un traitement (bouton encadré en rouge dans l’image ci-dessous).

Après avoir cliqué, l’explorateur de fichier s’ouvre.
Il faut choisir un fichier .json, exporté via l’interface du data pipeline, puis cliquez sur Ouvrir.
La page de saisie des informations générales de création s'affiche, pré-remplie :
- Modifier le nom si un traitement avec le meme nom existe déjà (tous environnements confondus, au clic sur
Valider, l'unicité est vérifiée) ; - Ajuster si besoin la description ;
- Choisir l'environnement ;
- Puis cliquez sur
Valider.
Le nouveau traitement (avec la configuration décrite dans le fichier json importé) est créé avec succès et vous êtes redirigé vers la page d’édition de celui-ci.
Si au moins une brique présente dans le traitement, ne l’est pas dans l’application, l’import sera impossible. Dans ce cas, un message énumérant les briques non-présentes s’affichera (comme dans l’image ci-dessous) :

Les images des briques manquantes (en général fournies par le développeur du traitement) doivent être importées : voir la procédure ci-dessus "Importer une nouvelle brique".
Lancer un traitement
Différentes options sont disponibles pour l'exécution d'un traitement, on vous explique cela.
Avant son lancement, des contôles préliminaires sont réalisés puis le traitement s'exécute sous la forme d'un flux.
Exécuter un flux
Sur la barre de tâches cliquez sur le bouton Déployer (encadré en rouge dans l’image ci-dessous).
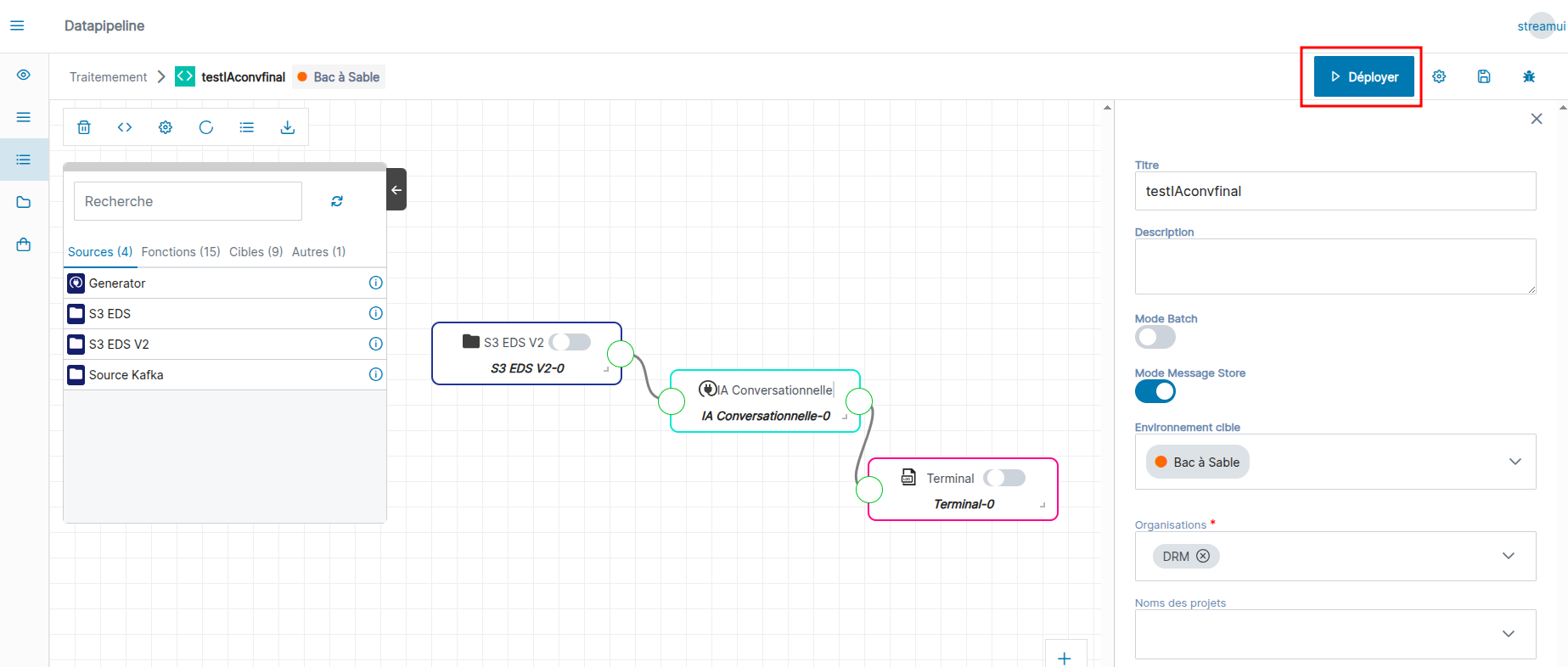
Des vérifications préalables de la bonne construction du traitement sont faites en amont de l'éxécution du flux dans le moteur d'exécution.
- En cas d'erreur, une pop-up descriptive des erreurs s’affiche (exemple dans l’image ci-dessous)
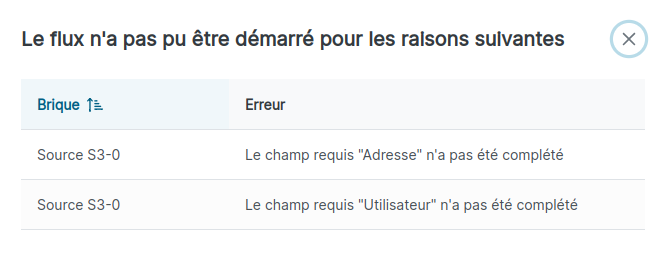
Le tableau descriptif des erreurs est composé de plusieurs informations :
- Brique : le nom de la brique en erreur ;
- Erreur : le nom du champ mal configuré.
Ces informations permettent de localiser et comprendre une erreur, afin de la corriger.
- Si le traitement est correctement construit, il est donc exécuté :
- un flux est créé ;
- le bouton passe de
DéployeràStopper, pour permettre à l'utilisateur d'arrêter le flux à tout moment ; - le panneau de logs apparait en bas de l’écran (encadré en rouge dans l’image ci-dessous).
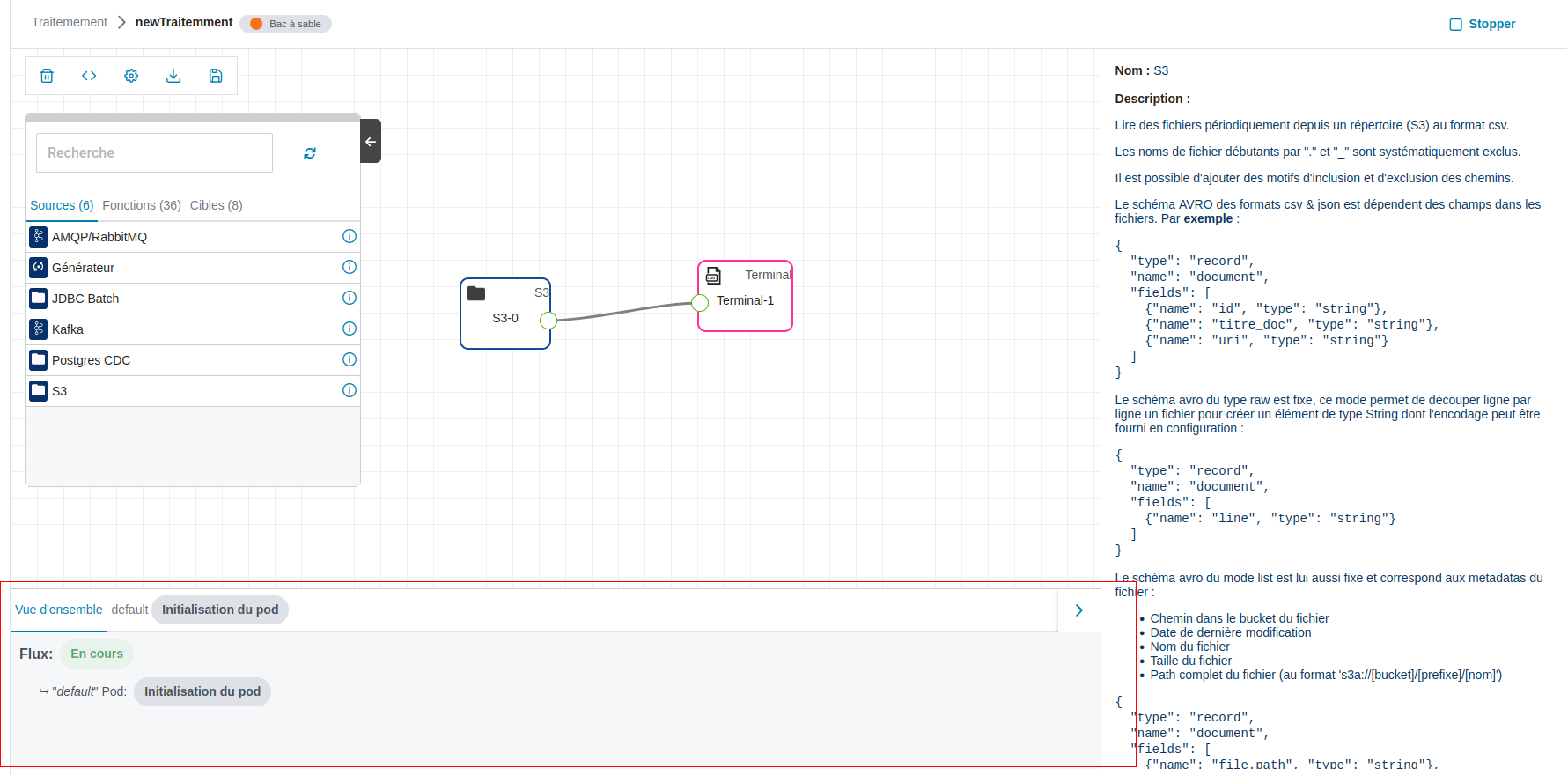
Pour plus de précisions concernant les logs : Consulter les logs.
Le flux apparaît alors dans la liste des flux : Consulter les flux.
Lancement en mode pas à pas
Pour lancer un flux en mode pas à pas appuyez sur le bouton en forme d'insecte (encadré en rouge dans l’image ci-dessous).
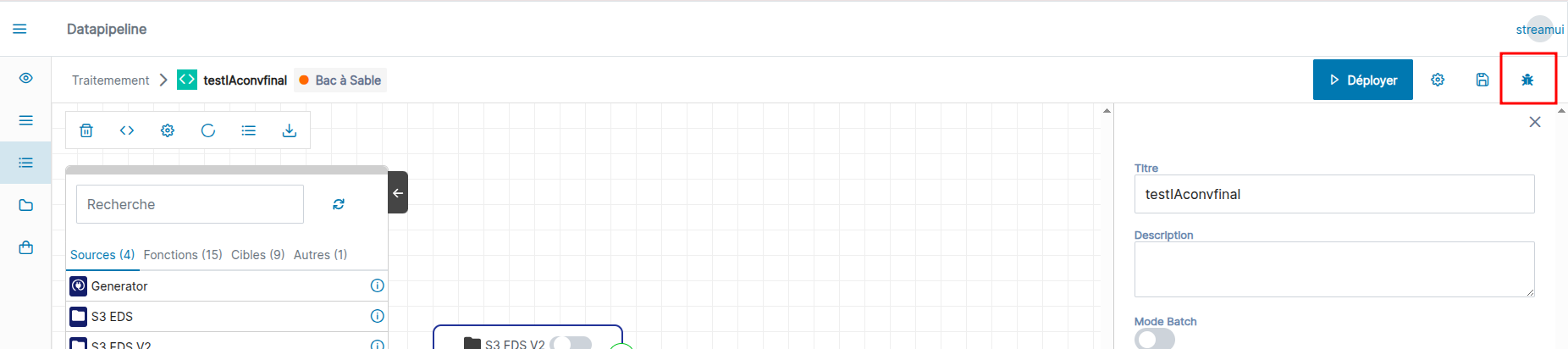
Dans cette nouvelle fenêtre vous pouvez choisir à gauche l'arbre que vous souhaitez suivre.
Le bouton Démarrer vous permet de lancer le flux, la source s'exécutera immédiatement. Le lancement en mode pas à pas n'est disponible qu'avec la source de type S3 EdS V2.
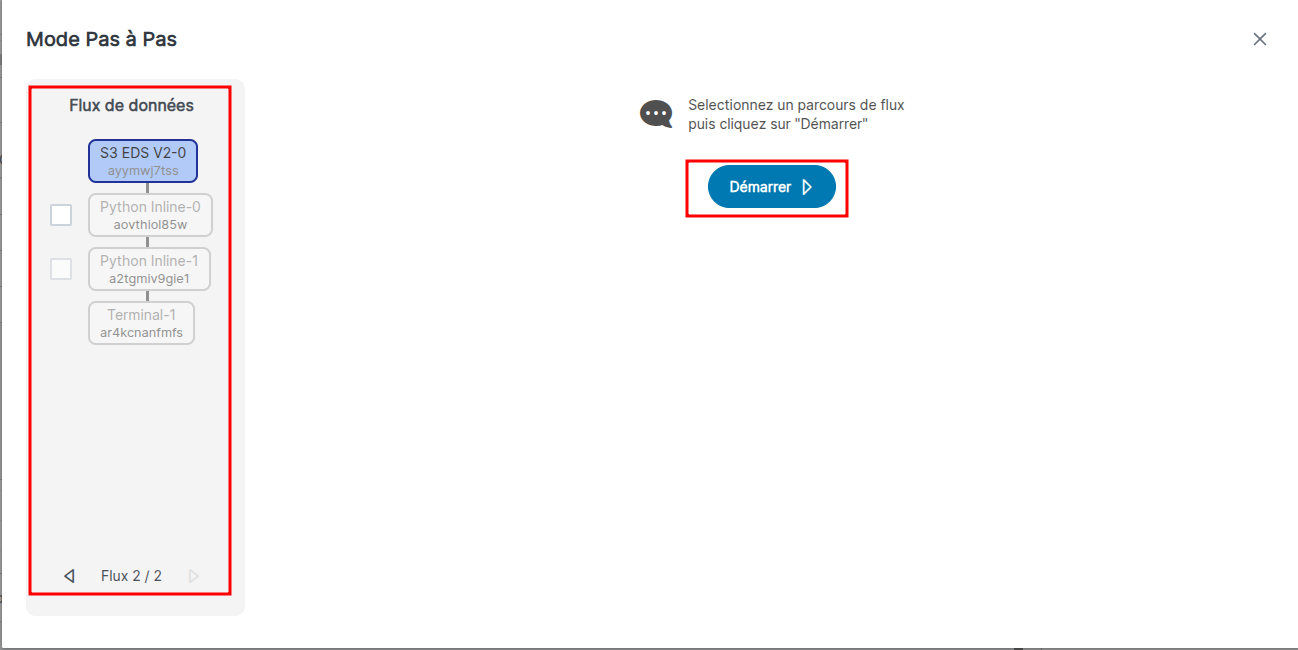
Une fois le lancement effectué vous pouvez :
- consulter les événements produit par votre source (au centre) ;
- jouer la/les la brique suivantes en cliquant sur les cases à cocher à gauche ;
- afficher les logs de la brique actuelle en changeant d'onglet en haut pour repérer une éventuelle erreur ;
- arrêter le flux de debogage en bas à gauche.
Le point vert ou rouge clignotant indique l'état de votre connexion avec le client qui vous fournit les données sortantes au fur et à mesure qu'elles sont produites.
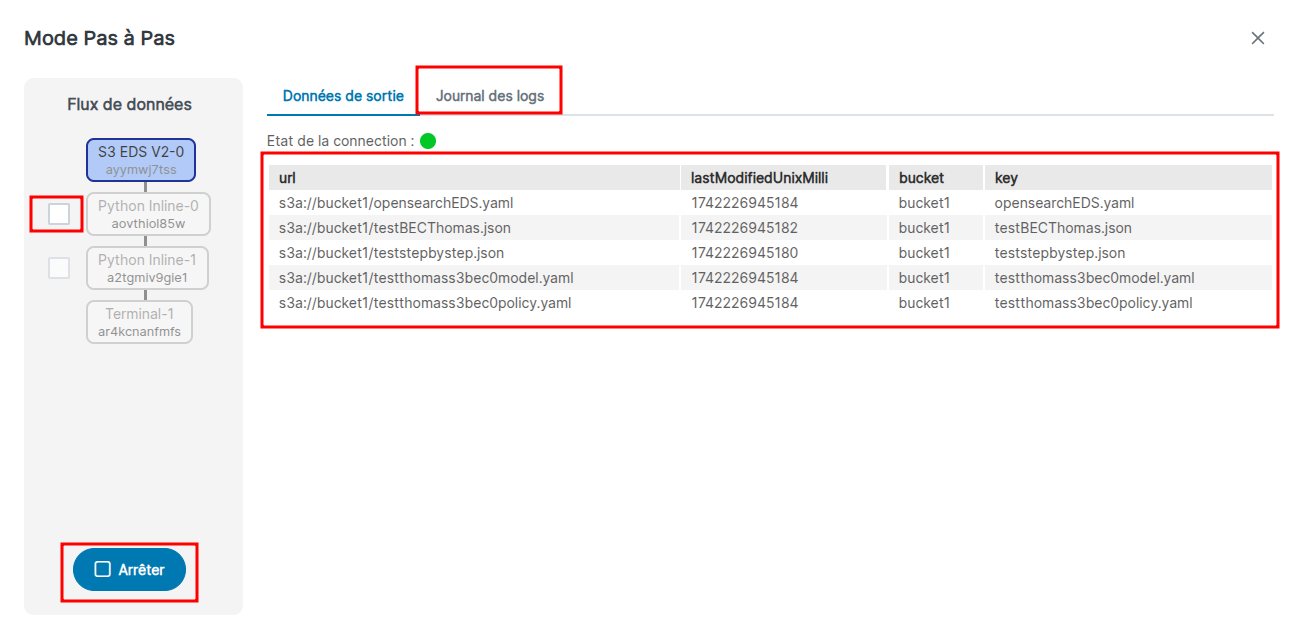
Le rafraichissement de l'affichage se fait toutes les 5 secondes, cela peut laisser penser à des incohérences d'affichage entre les briques.
Utilisation du mode avancé (facultatif)
Sur la barre des tâches, cliquez sur le bouton roue crantée, à droite du bouton d'éxécution. Une pop-up s’affiche. Par défaut, le mode avancé est désactivé. Le mode avancé permet de définir le nom du flux qui sera lancé par le worker temporal.
On peut alors donner un nom unique au flux. Cette option permet lorsqu'on le stoppe puis qu'on le relance de ne pas re-traiter les fichiers déjà traités.
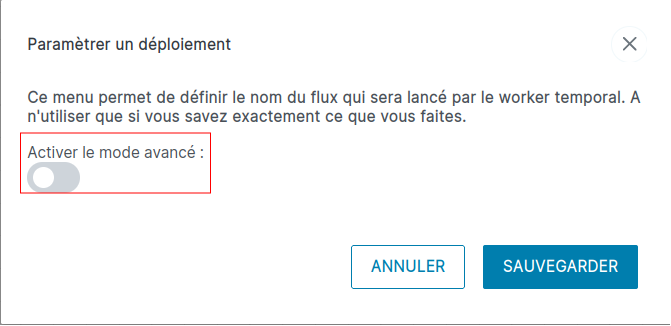
Une fois activé, saisissez un nom personnalisé de flux (ce nom accepte les caractères alphanumériques et également le caractère ”-”).
Cliquez sur le bouton SAUVEGARDER, pour enregistrer vos modifications. Le bouton de déploiement prend alors le libéllé Déployer (mode avancé)
Pour revenir à un déploiement standard, cliquez à nouveau sur le bouton roue crantée et cliquez sur Désactiver le mode avancé.
Cliquez sur SAUVEGARDER, pour que vos modifications soient enregistrés. Le bouton de déploiement revient au libéllé Déployer.
Application du BEC
Si une politique BEC est active sur un EDS où des données sont lues par le traitement, c'est le BEC de l'utilisateur connecté qui lance le flux qui va s'appliquer. Si l'utilisateur n'a pas les droits suffisants pour voir toutes les données, seules les données visibles sont traitées.
Stopper un flux
Sur la barre de tâches, cliquez sur le bouton Stopper (encadré en rouge dans l’image ci-dessous).
Contrairement à la pause, l'arrêt du traitement purge les événements en attente entre les briques

Le traitement est alors arrêté, le panneau de log en bas de l’écran reste affiché à l'écran.
Mettre en pause un flux
Appuyez sur le bouton pause (double barre parrallèle) :

Appuyez sur le bouton reprendre :

Le traitement a été en pause puis redémarré. Les données qui étaient en attente sont à leur tour exécutées.
Les données ne seront conservée que pour la durée indiqué dans le paramètre de traitement Rétention des données (en heures).
Mettre en pause une brique
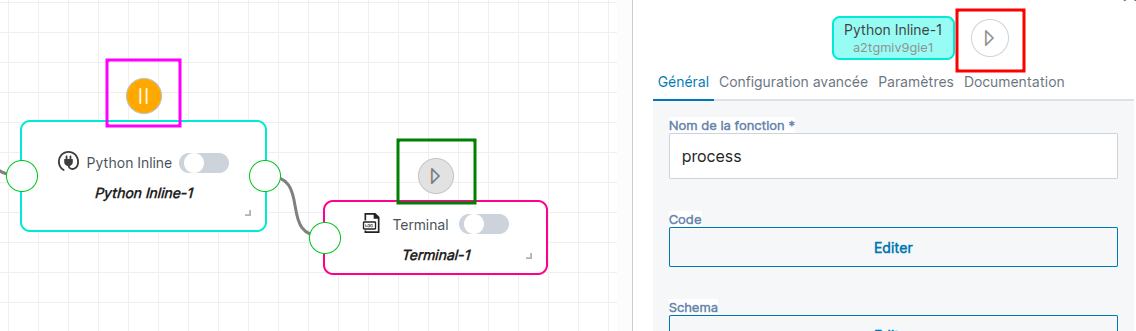
Dans cette images plusieurs éléments sont surlignés :
- rectangle vert : un bouton
playgris clignotant au dessus d'une brique indique qu'elle est actuellement en train de s'éxécuter ; - rectangle violet : un bouton
pauseorange au dessus d'une brique indique qu'elle est actuellement en pause ; - rectangle rouge : bouton permettant de mettre en pause ou d'éxécuter à nouveau la brique.
Une brique de type source ne peut pas être mise en pause.
Paramétrer un traitement
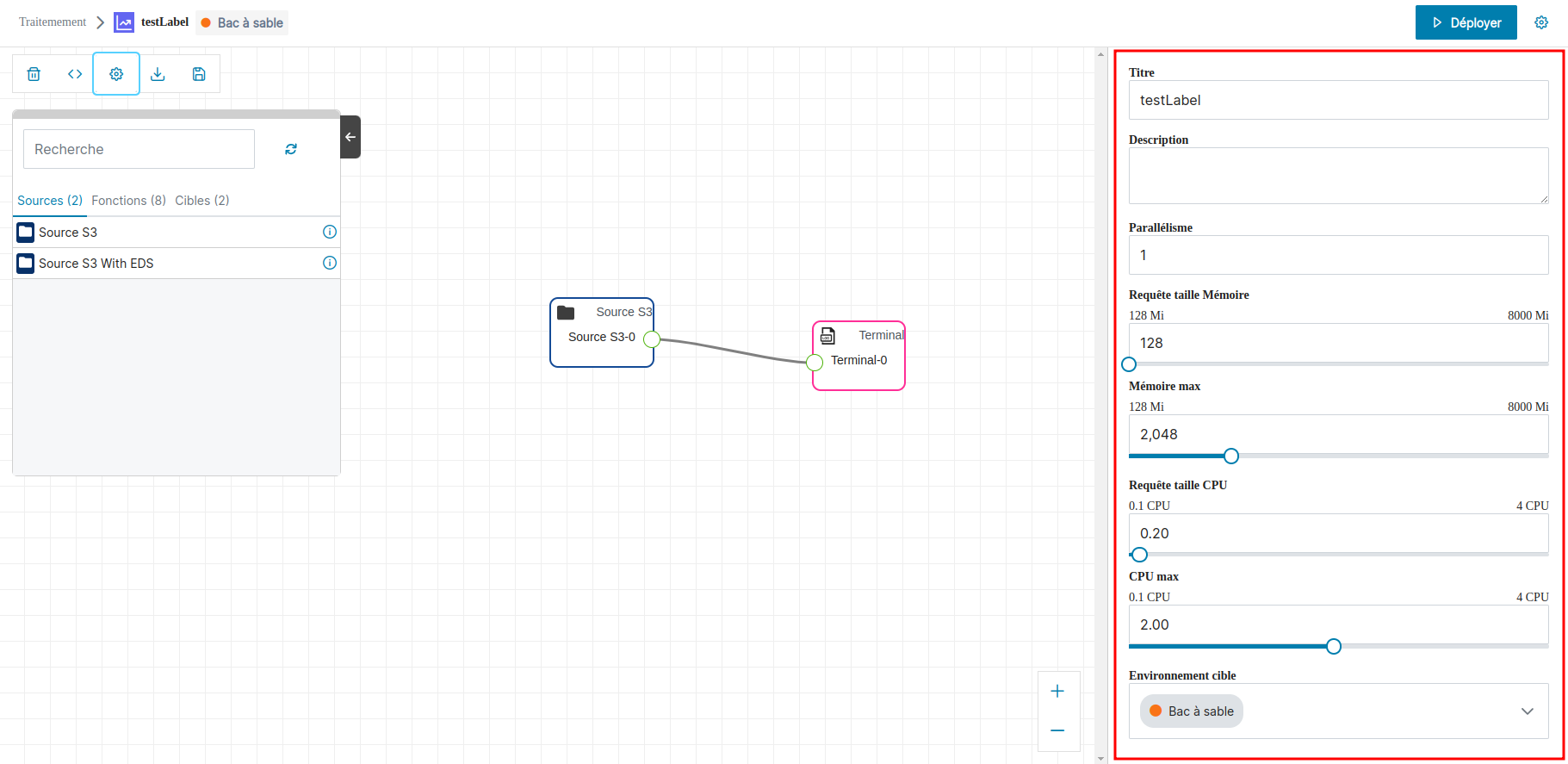
Modifications des paramètres
Vous pouvez modifier le titre, la description et les différents paramètres. Seul le mode, Analytique ou Basique, choisit lors de la création ne peut être modifié.
Champs avec barre de réglage
Les champs : Requête taille mémoire, mémoire max, requête taille cpu, cpu max, peuvent être modifiés à l’aide du champ de saisie ou le curseur de chaque champ. Pour valider la saisie d’un champ de saisie il faut cliquer sur la touche entrée. Dans les champs de saisie, si la valeur saisie est au-dessus du maximum défini, après la validation, c’est la valeur du max défini qui est retenue et pas la valeur saisie. Ce comportement permet d’éviter un dysfonctionnement du système.
Paramètres spécifiques disponibles
En mode Basique le paramètre :
- Mode Batch: permet de configurer le flux pour se terminer une fois tous les enregistrements récupérés à un instant T traité. Le mode par défaut est de rester en écoute de nouveaux éléments ;
- Rétention des données (en heures) : Permet de configurer la durée pendant laquelle un enregistrement reste en attente de traitement dans la file de tâche reliant deux briques. Ce paramètre est particulièrement utile dans le cas de flux stoppés ou de données rapidement créée mais longue à traiter ;
- Mode message Store : autorise le moteur à se servir d'un bucket S3 spécifique à la place de NATS pour faire transiter les événements d'une taille supérieur à 1 Mo.
En mode Analytique le paramètre:
Parallélisme: permet de traiter les événements proposés dans plusieurs exécutions parrallèles de votre traitement pour jouer rapidement l'intégralité des données ;Version du Runtime: permet de désigner la version de l'image des runtimes analytique disponibles qui sera utilisé lors du lancement de votre traitement.
Exécutions planifiées
Configuration
Il est possible pour un traitement de planifier des exécutions si :
- il s'agit d'un flux analytique ;
- il s'agit d'un flux basique avec le
mode Batchactif dans ses paramètres.
Pour ce faire, cliquer sur le bouton Editer de l'image ci-dessous :

Suite à cette action, un composant de configuration des exécutions automatiques est chargé :
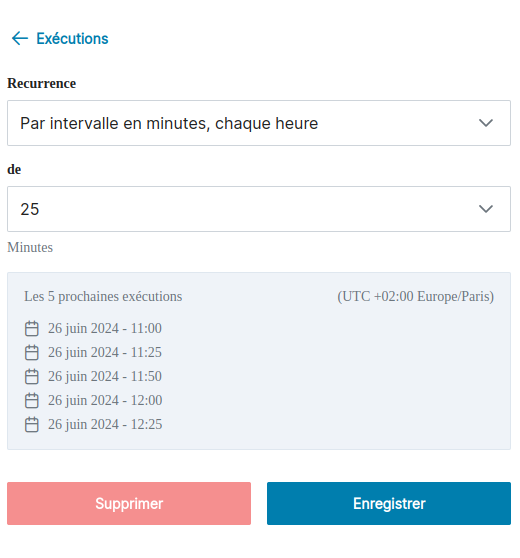
Sur cet écran, vous avez la possibilité de choisir le type de récurrence que vous souhaitez pour les exécutions automatiques :
- Par intervalle en minutes, chaque heure ;
- Toutes les heures ;
- Tous les jours ;
- Toutes les semaines ;
- Tous les mois ;
- Tous les ans.
Selon ce choix, le formulaire de configuration se met à jour. Les prochaines exécutions prévues sont affichées dans un encart sous le formulaire de configuration.
Lorsque le champ Récurrence est modifié, alors les champs disponibles dans le formulaire de configuration sont également mis à jour.
Ainsi, par exemple, lorsque vous choisissez la récurrence "Chaque année", vous aurez à disposition un champ "calendrier" permettant de choisir une date précise, ainsi qu'un champ "horaire" pour sélectionner une heure.
Le composant affichant les prochaines exécutions se met à jour en direct, lorsque vous modifiez les champs du formulaire.
Lorsque vous avez fini de configurer la table de planification, vous pouvez appuyer sur Enregistrer. Cela vous redirige sur la page de configuration du datapipeline. Vous constatez que sur cette page apparaît également les deux prochaines planifications prévues.
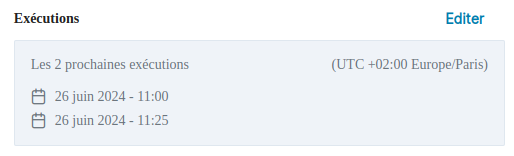
Suppression
Il y a la possibilité de supprimer la configuration des exécutions automatiques. Pour celà, éditez la table de planification.
Lorsque vous arrivez sur la page de configuration, un bouton Supprimer est disponible. Au clic, une pop-up s'affiche pour confirmer votre action. Cliquez sur Oui.

Vous êtes alors redirigé sur la page de configuration du datapipeline et sous le titre "Exécutions", vous lisez le texte "Pas d'exécutions planifiées".
Checkpoint et lancement avancé
A côté du bouton Déployer une roue crantée vous permet d'accéder au lancement avancé.

Le lancement avancé est un mode qui permet l'utilisation du checkpointing, c'est à dire de ne pas traiter à chaque nouveau lancement tous les fichiers, mais seulement ceux qui n'ont pas été traités. Pour paramétrer le lancement avancé il suffit d'activer l'option et de donner un nom au flux :
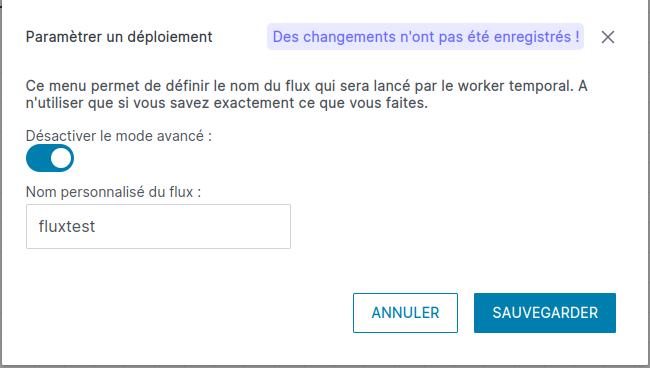
Contrairement au mode normal où un nouveau numéro de flux aléatoire est généré à chaque lancement, ici votre flux sera systèmatiquement relancé avec le même nom :
![]()
Une fois le déploiement avancé actif le bouton de déploiement change de nom :

L'utilisation du checkpointing n'est pour l'instant possible qu'avec une source S3. Le mode de déploiement avancé seul ne suffit pas, il faut également que l'option de checkpoint soient activée dans votre briques de source S3 :
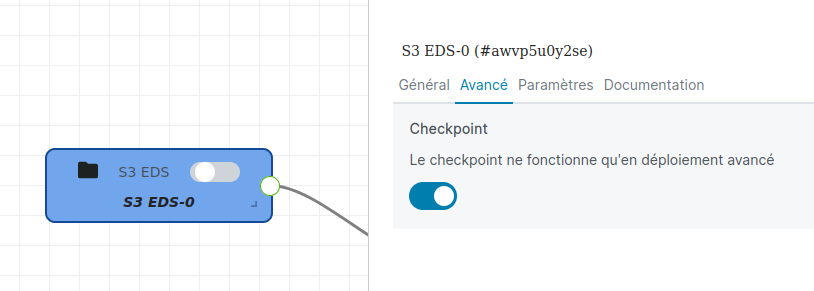
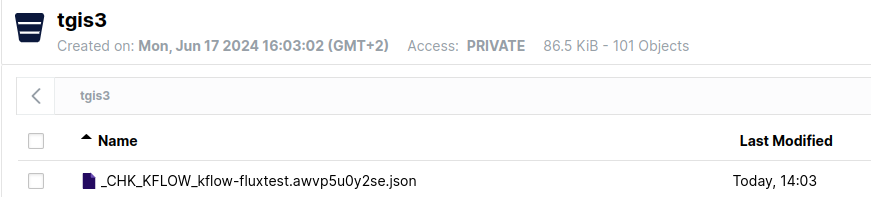
Cette option de checkpoint fait apparaitre des fichiers de checkpoint dans votre bucket source, qui sont ignoré lors d'une opération de listing des fichiers :
Validation des modifications
Pour que les modifications soit prises en compte, il faudra bien penser à les sauvegarder en cliquant sur le bouton entouré en bleu sur l'image ci-dessous, puis stopper et redémarrer le flux si celui est en cours.
Lorsque le flux est redémarré, il est en attente de son prochain créneau d'exécution.
Sauvegarder un traitement
Cette procédure explique comment sauvegarder un traitement. Cependant, une sauvegarde automatique est en place toutes les 5 minutes pour éviter la perte en cas de rupture réseau ou d'arrêt inopiné du navigateur.
Etape 1
Prérequis : être placé sur la page d’éditeur de traitement (explication [ici]). L’icône de sauvegarde sur la barre de tâches est présentée entourée en bleu sur l'image ci-dessous.
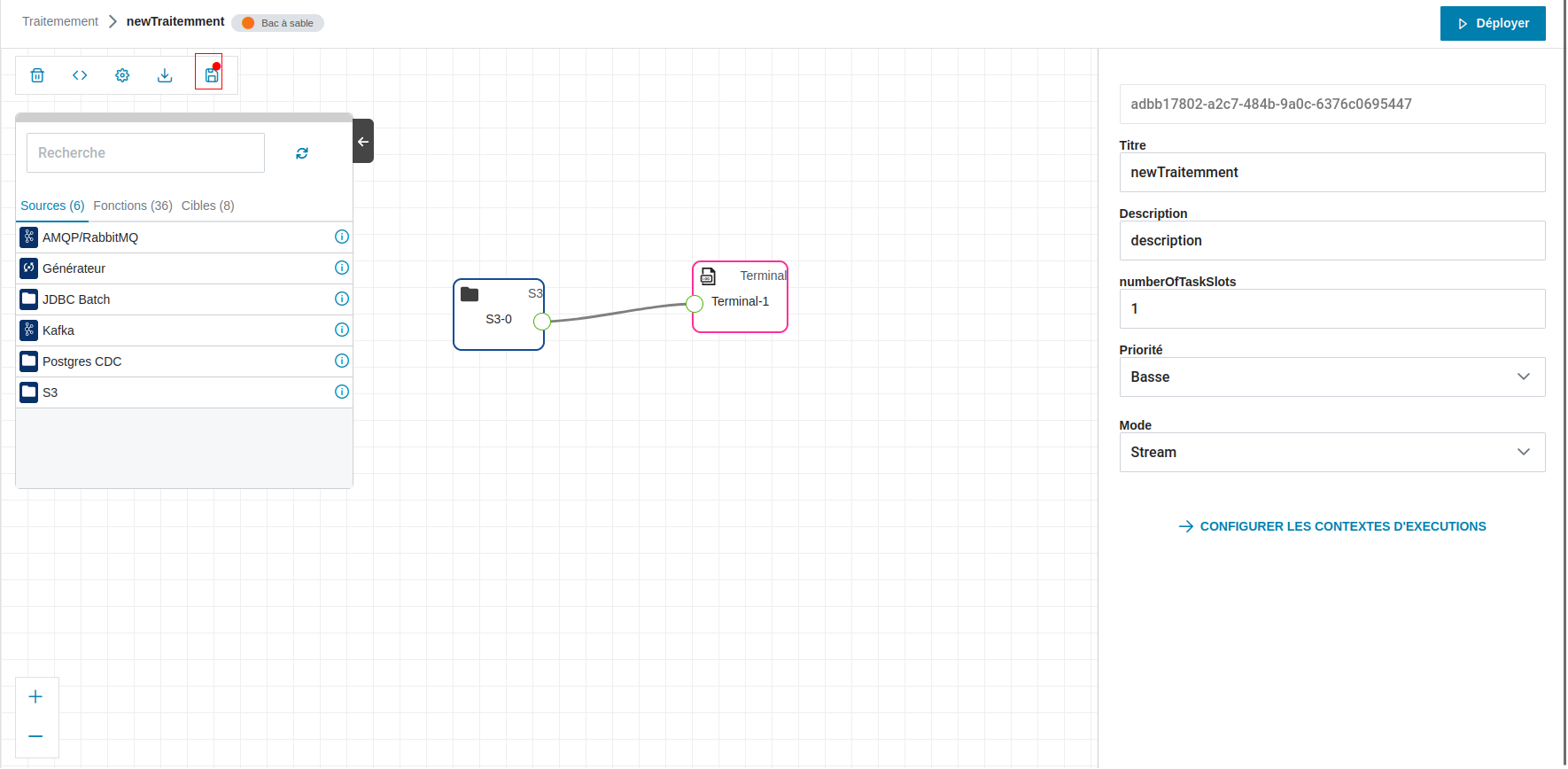
Quand vous effectuez une de ces actions sur le traitement ouvert :
- Suppression d’un graphique
- Ajout/suppression d’une brique
- Ajout/suppression d’un lien
- Modification d’un paramètre d’une brique
Un petit cercle s’ajoute en bas à droite de l’icône de sauvegarde (encadré en rouge dans l’image ci-dessous). Cette icône indique qu’il y a au moins un changement non sauvegardé. Cliquez sur l’icône.
Si un traitement est non sauvegardé et que l’on souhaite le quitter, sans prendre en compte les changements, un pop-up de confirmation s’affichera et vous demandera si vous souhaitez réellement quitter sans sauvegarder vos changements.
Supprimer un traitement
Action à réaliser
Etre placé sur la page des traitements (explication : [ici]).
Une fois que la page des traitements est affichée, Sur la ligne du traitement que vous souhaitez supprimer, dans la colonne “Action”, cliquez sur l'icône représentant une poubelle.
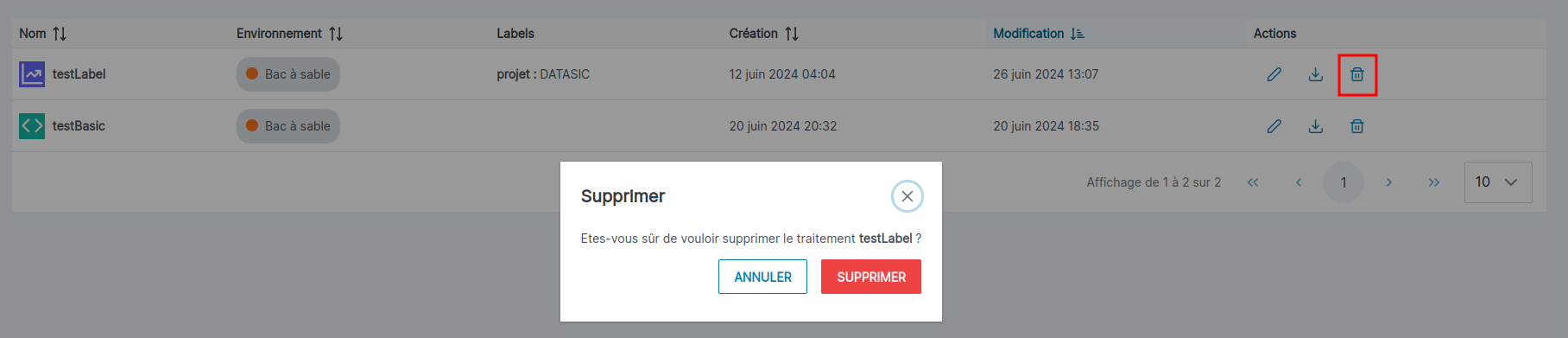
Une pop-pup de confirmation s’affiche, s’assurer que c’est bien le nom du traitement que l’on désire supprimer. Cliquez sur le bouton “Supprimer”.